我注意到在使用Azure SQL数据库时,使用EntityFramework生成的参数化查询存在性能差异。
我有一张带有varchar(30)主键的表格,当我尝试使用主键从该表格中获取值时,EntityFramework创建了一个参数化查询,其中NVARCHAR(4000)作为数据类型。
这会在Azure SQL数据库上生成一个非常奇怪的执行计划。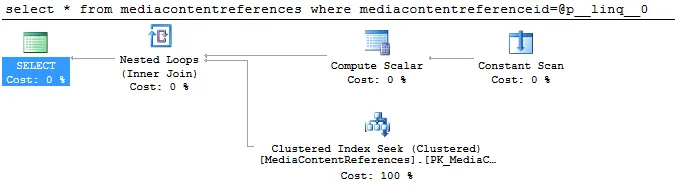 这看起来像是Azure SQL服务器执行计划计算中的缺陷。
这看起来像是Azure SQL服务器执行计划计算中的缺陷。
是否有可能更改Entity Framework创建查询的行为?
我已经阅读了一些关于此问题的文章,但没有找到解决方案。 为什么Code First / EF在原始SQL命令中使用'nvarchar(4000)'字符串? 为什么Entity Framework生成大型参数?如何减少它们?
我有一张带有varchar(30)主键的表格,当我尝试使用主键从该表格中获取值时,EntityFramework创建了一个参数化查询,其中NVARCHAR(4000)作为数据类型。
DECLARE @p__linq__0 nvarchar(4000)
SET @p__linq__0 ='ehenurqp0kpql76kjsw3'
select * from mediacontentreferences where mediacontentreferenceid=@p__linq__0
这会在Azure SQL数据库上生成一个非常奇怪的执行计划。

由于使用全表扫描的索引扫描,效率相当低。
如果我使用正确数据类型的参数,执行计划将使用主键索引。
DECLARE @p__linq__1 varchar(30)
SET @p__linq__1 ='ehenurqp0kpql76kjsw3'
select * from mediacontentreferences where mediacontentreferenceid=@p__linq__1

这看起来像是Azure SQL服务器执行计划计算中的缺陷。是否有可能更改Entity Framework创建查询的行为?
我已经阅读了一些关于此问题的文章,但没有找到解决方案。 为什么Code First / EF在原始SQL命令中使用'nvarchar(4000)'字符串? 为什么Entity Framework生成大型参数?如何减少它们?