我不知道是否有更好的替代方案可以直接给你结果,但是这里有一种方法可能适合你的需求。
您的输入:
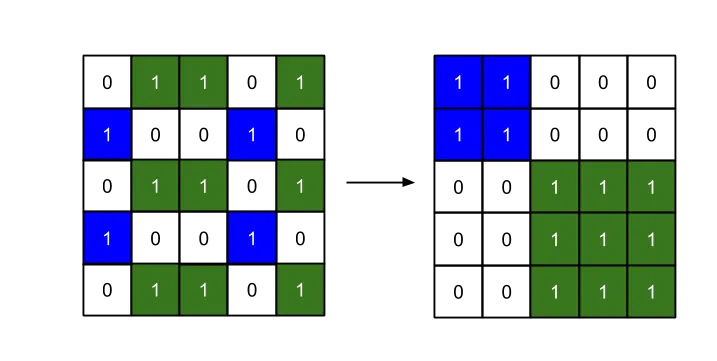
>> A
A =
0 1 1 0 1
1 0 0 1 0
0 1 1 0 1
1 0 0 1 0
0 1 1 0 1
方法一
将第一行和第一列作为列掩码(maskCol)和行掩码(maskRow)。
获取掩码,其中的值在第一行和第一列中均包含一个。
maskRow = A(:,1)==1;
maskCol = A(1,:)~=1;
重排行(根据行掩码)
out = [A(maskRow,:);A(~maskRow,:)];
类似于这样:
out =
1 0 0 1 0
1 0 0 1 0
0 1 1 0 1
0 1 1 0 1
0 1 1 0 1
重新排列列(根据列掩码)
out = [out(:,maskCol),out(:,~maskCol)]
能够得到期望的结果:
out =
1 1 0 0 0
1 1 0 0 0
0 0 1 1 1
0 0 1 1 1
0 0 1 1 1
只是检查索引是否在它们应该的位置,或者您是否想要对应的重新排列索引 ;)
重新排列之前:
idx = reshape(1:25,5,[])
idx =
1 6 11 16 21
2 7 12 17 22
3 8 13 18 23
4 9 14 19 24
5 10 15 20 25
重新排列后(与我们之前执行的同一过程)
outidx = [idx(maskRow,:);idx(~maskRow,:)];
outidx = [outidx(:,maskCol),outidx(:,~maskCol)]
输出:
outidx =
2 17 7 12 22
4 19 9 14 24
1 16 6 11 21
3 18 8 13 23
5 20 10 15 25
方法2
对于通用情况,如果您不知道矩阵,请按照以下步骤查找maskRow和maskCol
逻辑:
取第一行。将其视为列掩码(maskCol)。
对于第2行到最后一行,重复以下过程。
将当前行与maskCol进行比较。
如果任何一个值与maskCol匹配,则找到元素
智能逻辑或并将其更新为新的maskCol
重复此过程直到最后一行。
使用列迭代查找maskRow的相同过程。
代码:
maskCol = A(1,:);
for ii = 2:size(A,1)
if sum(A(ii,:) & maskCol)>0
maskCol = maskCol | A(ii,:);
end
end
maskCol = ~maskCol;
maskRow = A(:,1);
for ii = 2:size(A,2)
if sum(A(:,ii) & maskRow)>0
maskRow = maskRow | A(:,ii);
end
end
这里有一个示例可以尝试一下:
A = [0 0 1 0 1
0 0 0 1 0
0 1 1 0 0
1 0 0 1 0
0 1 0 0 1];
然后,重复之前的步骤:
out = [A(maskRow,:);A(~maskRow,:)];
out = [out(:,maskCol),out(:,~maskCol)];
这是翻译的结果:
这里是结果:
>> out
out =
0 1 0 0 0
1 1 0 0 0
0 0 0 1 1
0 0 1 1 0
0 0 1 0 1
注意:这种方法可能适用于大多数情况,但仍然可能在一些罕见的情况下失败。
这里是一个例子:
%// this works well.
A = [0 0 1 0 1 0
1 0 0 1 0 0
0 1 0 0 0 1
1 0 0 1 0 0
0 0 1 0 1 0
0 1 0 0 1 1]
%// This may not
%// Second col, last row changed to zero from one
A = [0 0 1 0 1 0
1 0 0 1 0 0
0 1 0 0 0 1
1 0 0 1 0 0
0 0 1 0 1 0
0 0 0 0 1 1]
为什么失败了?
当我们循环遍历每一行(以找到列掩码)时,例如,当我们移动到第三行时,没有任何一列与第一行(当前的 maskCol)匹配。因此,第三行(第二个元素)所携带的唯一信息被丢失。
这可能是一个罕见的情况,因为其他某一行可能仍然包含相同的信息。请参见第一个示例。在那里,第三行的任何元素都不与第一行匹配,但由于最后一行具有相同的信息(第二个元素为1),因此它给出了正确的结果。只有在类似这种罕见情况下才可能发生类似的事情。尽管如此,了解这个缺点还是好的。
方法3
这是蛮力备选方案。如果您认为之前的情况可能会失败,可以应用该方案。在这里,我们使用 while 循环 运行先前的代码(查找行和列掩码)多次,使用更新的 maskCol ,以便找到正确的掩码。
程序:
maskCol = A(1,:);
count = 1;
while(count<3)
for ii = 2:size(A,1)
if sum(A(ii,:) & maskCol)>0
maskCol = maskCol | A(ii,:);
end
end
count = count+1;
end
以下是一个例子,使用了while循环来解决之前方法无法解决的问题。
不使用暴力破解:
>> out
out =
1 0 1 0 0 0
1 0 1 0 0 0
0 0 0 1 1 0
0 1 0 0 0 1
0 0 0 1 1 0
0 0 0 0 1 1
使用暴力循环:
>> out
out =
1 1 0 0 0 0
1 1 0 0 0 0
0 0 0 1 1 0
0 0 1 0 0 1
0 0 0 1 1 0
0 0 0 0 1 1
得到正确结果所需的迭代次数可能会有所不同。但是保持一个良好的次数是安全的。
祝你好运!