我有一个包含两列的表格,如下所示:
CREATE TABLE test_lin
(
Cola INT,
Colb INT
);
INSERT INTO test_lin VALUES(1,2);
INSERT INTO test_lin VALUES(1,3);
INSERT INTO test_lin VALUES(1,4);
INSERT INTO test_lin VALUES(1,5);
INSERT INTO test_lin VALUES(1,3);
INSERT INTO test_lin VALUES(2,4);
INSERT INTO test_lin VALUES(2,6);
INSERT INTO test_lin VALUES(2,7);
INSERT INTO test_lin VALUES(2,4);
INSERT INTO test_lin VALUES(2,6);
注意:现在我想只显示那些重复出现超过一次的记录。就像在我的情况下,(1,3),(2,4)和(2,6)这些记录在表中重复出现。
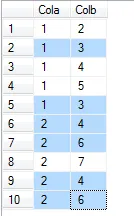
我想从结果集中删除单个出现的记录。如下图所示,单个出现的记录如下:
