更新:我找到了解决方法,请参见我的下面的回答。
现在的问题是,我还没有在任何地方存储这些数据。经理一直是动态计算的。我有数百万张票务跨越几个具有相同架构的数据库需要填充此表。我希望以尽可能高效的方式完成此操作,但是对于优化我正在使用的查询没有成功。
这个查询在包含超过1.7百万张票的模式上运行需要一个多小时。对于我拥有的维护窗口来说,这是无法接受的。此外,它甚至不能处理计算manager_resolved字段,因为将其合并到同一查询中会将查询时间推到极限。我目前的倾向是将它们分开,并使用UPDATE填充manager_resolved字段,但我不确定。
最后,这是该查询SELECT部分的EXPLAIN输出:
非常感谢您的阅读!
我的问题
如何优化此查询以最小化停机时间? 我需要更新50多个架构,其中门票数量从100,000到200万不等。 是否建议一次性设置tickets_extra中的所有字段? 我感觉这里有一个解决方案,但我只是没有看到。 我已经为这个问题苦恼了一天多。
另外,我最初尝试过不使用子查询,但是性能比我现在拥有的要差得多。
背景
我正在尝试为需要运行的报告优化数据库。 我需要聚合的字段非常耗费计算资源,因此我正在对我的现有模式进行一些去规范化以适应此报告。请注意,我通过删除一些不相关的列来简化了票务表。
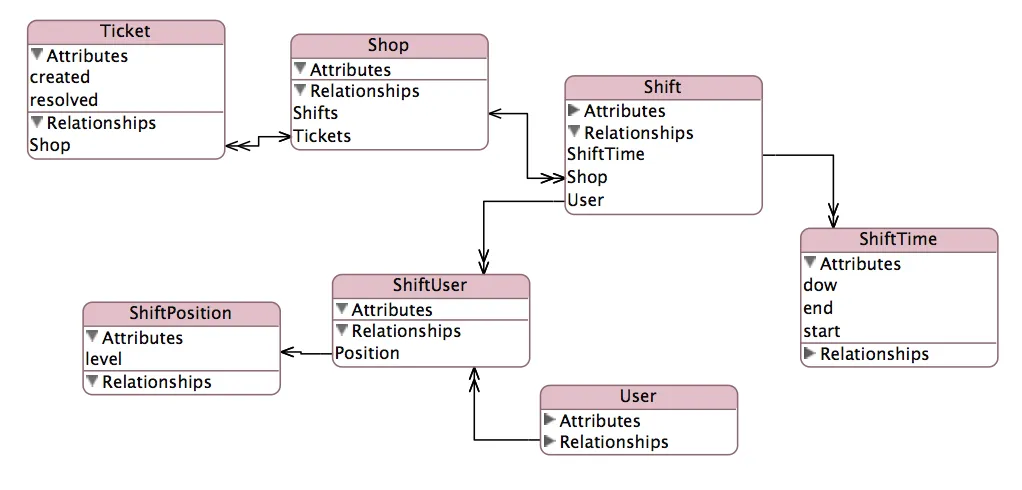
我的报告将根据创建时经理和解决时经理对门票计数进行聚合。 这种复杂的关系在此处进行了说明:
(来源:mosso.com)
{kind=link}
为了避免在运行时需要半打联接计算此关系,我已将以下表添加到我的架构中:
mysql> show create table tickets_extra\G
*************************** 1. row ***************************
Table: tickets_extra
Create Table: CREATE TABLE `tickets_extra` (
`ticket_id` int(11) NOT NULL,
`manager_created` int(11) DEFAULT NULL,
`manager_resolved` int(11) DEFAULT NULL,
PRIMARY KEY (`ticket_id`),
KEY `manager_created` (`manager_created`,`manager_resolved`),
KEY `manager_resolved` (`manager_resolved`,`manager_created`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
1 row in set (0.00 sec)
现在的问题是,我还没有在任何地方存储这些数据。经理一直是动态计算的。我有数百万张票务跨越几个具有相同架构的数据库需要填充此表。我希望以尽可能高效的方式完成此操作,但是对于优化我正在使用的查询没有成功。
INSERT INTO tickets_extra (ticket_id, manager_created)
SELECT
t.id,
su.user_id
FROM (
SELECT
t.id,
shift_times.shift_id AS shift_id
FROM tickets t
JOIN shifts ON t.shop_id = shifts.shop_id
JOIN shift_times ON (shifts.id = shift_times.shift_id
AND shift_times.dow = DAYOFWEEK(t.created)
AND TIME(t.created) BETWEEN shift_times.start AND shift_times.end)
) t
LEFT JOIN shifts_users su ON t.shift_id = su.shift_id
LEFT JOIN shift_positions ON su.shift_position_id = shift_positions.id
WHERE shift_positions.level = 1
这个查询在包含超过1.7百万张票的模式上运行需要一个多小时。对于我拥有的维护窗口来说,这是无法接受的。此外,它甚至不能处理计算manager_resolved字段,因为将其合并到同一查询中会将查询时间推到极限。我目前的倾向是将它们分开,并使用UPDATE填充manager_resolved字段,但我不确定。
最后,这是该查询SELECT部分的EXPLAIN输出:
*************************** 1. row ***************************
id: 1
select_type: PRIMARY
table: <derived2>
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 167661
Extra:
*************************** 2. row ***************************
id: 1
select_type: PRIMARY
table: su
type: ref
possible_keys: shift_id_fk_idx,shift_position_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: t.shift_id
rows: 5
Extra: Using where
*************************** 3. row ***************************
id: 1
select_type: PRIMARY
table: shift_positions
type: ALL
possible_keys: PRIMARY
key: NULL
key_len: NULL
ref: NULL
rows: 6
Extra: Using where; Using join buffer
*************************** 4. row ***************************
id: 2
select_type: DERIVED
table: t
type: ALL
possible_keys: fk_tickets_shop_id
key: NULL
key_len: NULL
ref: NULL
rows: 173825
Extra:
*************************** 5. row ***************************
id: 2
select_type: DERIVED
table: shifts
type: ref
possible_keys: PRIMARY,shop_id_fk_idx
key: shop_id_fk_idx
key_len: 4
ref: dev_acmc.t.shop_id
rows: 1
Extra:
*************************** 6. row ***************************
id: 2
select_type: DERIVED
table: shift_times
type: ref
possible_keys: shift_id_fk_idx
key: shift_id_fk_idx
key_len: 4
ref: dev_acmc.shifts.id
rows: 4
Extra: Using where
6 rows in set (6.30 sec)
非常感谢您的阅读!
shift_times是InnoDB类型,而其他所有表都是MyISAM类型。也许连接两个不同引擎类型的表可能会导致一些减速。暂时就这些了。 - Ionuț G. Stan