每天我们有高达30GB的GZipped日志文件。每个文件包含100,000行,压缩后大小在6到8MB之间。简化的代码已剥离解析逻辑,并利用Parallel.ForEach循环。
处理的最大行数峰值出现在两个NUMA节点、32个逻辑CPU盒子(Intel Xeon E7-2820 @ 2 GHz)的MaxDegreeOfParallelism为8时:
using System;
using System.Collections.Concurrent;
using System.Linq;
using System.IO;
using System.IO.Compression;
using System.Threading.Tasks;
namespace ParallelLineCount
{
public class ScriptMain
{
static void Main(String[] args)
{
int maxMaxDOP = (args.Length > 0) ? Convert.ToInt16(args[0]) : 2;
string fileLocation = (args.Length > 1) ? args[1] : "C:\\Temp\\SomeFiles" ;
string filePattern = (args.Length > 1) ? args[2] : "*2012-10-30.*.gz";
string fileNamePrefix = (args.Length > 1) ? args[3] : "LineCounts";
Console.WriteLine("Start: {0}", DateTime.UtcNow.ToString("yyyy-MM-ddTHH:mm:ss.fffffffZ"));
Console.WriteLine("Processing file(s): {0}", filePattern);
Console.WriteLine("Max MaxDOP to be used: {0}", maxMaxDOP.ToString());
Console.WriteLine("");
Console.WriteLine("MaxDOP,FilesProcessed,ProcessingTime[ms],BytesProcessed,LinesRead,SomeBookLines,LinesPer[ms],BytesPer[ms]");
for (int maxDOP = 1; maxDOP <= maxMaxDOP; maxDOP++)
{
// Construct ConcurrentStacks for resulting strings and counters
ConcurrentStack<Int64> TotalLines = new ConcurrentStack<Int64>();
ConcurrentStack<Int64> TotalSomeBookLines = new ConcurrentStack<Int64>();
ConcurrentStack<Int64> TotalLength = new ConcurrentStack<Int64>();
ConcurrentStack<int> TotalFiles = new ConcurrentStack<int>();
DateTime FullStartTime = DateTime.Now;
string[] files = System.IO.Directory.GetFiles(fileLocation, filePattern);
var options = new ParallelOptions() { MaxDegreeOfParallelism = maxDOP };
// Method signature: Parallel.ForEach(IEnumerable<TSource> source, Action<TSource> body)
Parallel.ForEach(files, options, currentFile =>
{
string filename = System.IO.Path.GetFileName(currentFile);
DateTime fileStartTime = DateTime.Now;
using (FileStream inFile = File.Open(fileLocation + "\\" + filename, FileMode.Open))
{
Int64 lines = 0, someBookLines = 0, length = 0;
String line = "";
using (var reader = new StreamReader(new GZipStream(inFile, CompressionMode.Decompress)))
{
while (!reader.EndOfStream)
{
line = reader.ReadLine();
lines++; // total lines
length += line.Length; // total line length
if (line.Contains("book")) someBookLines++; // some special lines that need to be parsed later
}
TotalLines.Push(lines); TotalSomeBookLines.Push(someBookLines); TotalLength.Push(length);
TotalFiles.Push(1); // silly way to count processed files :)
}
}
}
);
TimeSpan runningTime = DateTime.Now - FullStartTime;
// Console.WriteLine("MaxDOP,FilesProcessed,ProcessingTime[ms],BytesProcessed,LinesRead,SomeBookLines,LinesPer[ms],BytesPer[ms]");
Console.WriteLine("{0},{1},{2},{3},{4},{5},{6},{7}",
maxDOP.ToString(),
TotalFiles.Sum().ToString(),
Convert.ToInt32(runningTime.TotalMilliseconds).ToString(),
TotalLength.Sum().ToString(),
TotalLines.Sum(),
TotalSomeBookLines.Sum().ToString(),
Convert.ToInt64(TotalLines.Sum() / runningTime.TotalMilliseconds).ToString(),
Convert.ToInt64(TotalLength.Sum() / runningTime.TotalMilliseconds).ToString());
}
Console.WriteLine();
Console.WriteLine("Finish: " + DateTime.UtcNow.ToString("yyyy-MM-ddTHH:mm:ss.fffffffZ"));
}
}
}
以下是结果摘要,可以清晰地看到MaxDegreeOfParallelism=8处有明显的高峰:
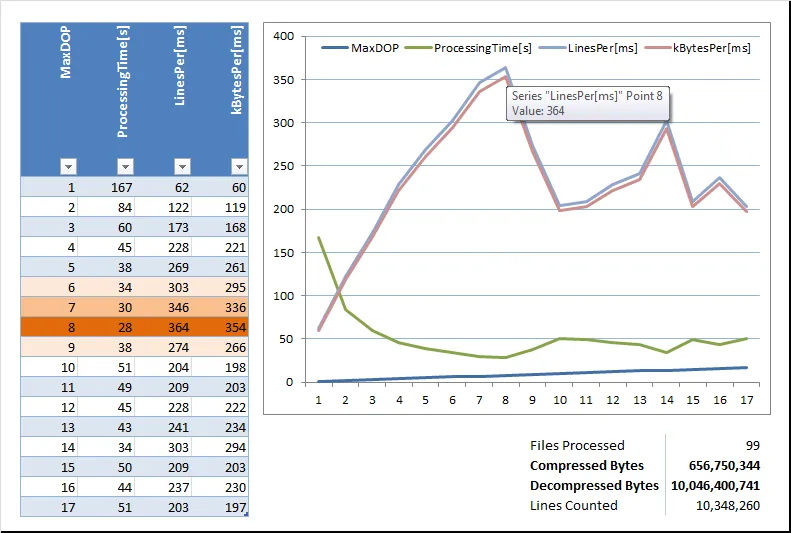
CPU负载(此处显示的是聚合值,大部分负载都在单个NUMA节点上,即使DOP在20到30之间):

我发现让CPU负载超过95%的唯一方法是将文件分成4个不同的文件夹并执行相同的命令4次,每次针对所有文件的子集。
有人能找到瓶颈吗?