如何在SQL Server中将包含矩阵的字符串分割成表格?字符串具有列和行分隔符。
假设我有一个字符串:
假设我有一个字符串:
declare @str varchar(max)='A,B,C;D,E,F;X,Y,Z';
预期结果(分成三列):
+---+---+---+
| A | B | C |
+---+---+---+
| D | E | F |
+---+---+---+
| X | Y | Z |
+---+---+---+
我正在寻找一种通用解决方案,它没有定义列数和行数。因此字符串为:
declare @str varchar(max)='A,B;D,E';
| will be split into | table with two columns: |
+---+---+
| A | B |
+---+---+
| D | E |
+---+---+
insert into dbo.temp values (...)。虽然这种方法非常快,但有一个小缺点,因为它需要先创建具有正确列数的表格。我在下面的问题答案中提供了这种方法,只是为了让问题简短明了。
另一个想法是将字符串写入服务器上的CSV文件,然后使用bulk insert导入。虽然我不知道如何做以及第一和第二个想法的性能如何。
我提出这个问题的原因是因为我想从Excel导入数据到SQL Server。由于我尝试了不同的ADO方法,所以当字符串长度增加时,通过发送矩阵字符串的方法是压倒性的胜利。我在这里问了一个相似的问题:将Excel范围转换为VBA字符串,其中您可以找到有关如何从Excel范围准备此类字符串的建议。
悬赏 我决定授予Matt。 我高度评价Sean Lange的回答。谢谢Sean。我喜欢Matt的答案因为它简单而简洁。除了Matt和Sean之外的不同方法可以并行使用,因此目前我不接受任何答案(更新:几个月后,我接受了Matt的答案)。我感谢Ahmed Saeed提出的使用VALUES的想法,因为这是我开始的答案的一个很好的演变。当然,它无法与Matt或Sean匹敌。我投票支持每个答案。我将感激您对使用这些方法的任何反馈。感谢您的关注。
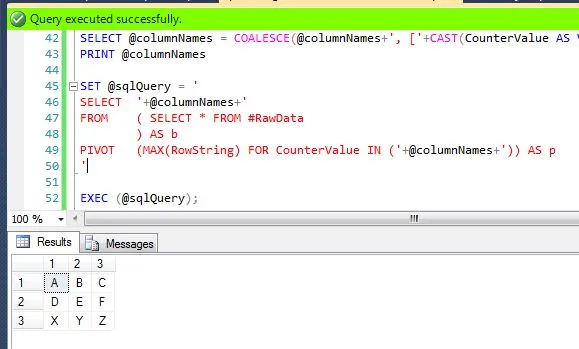
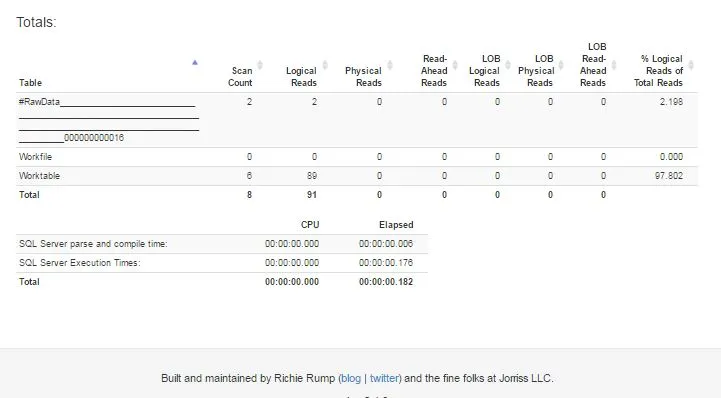
select * into table的方式插入会比insert into table select * ...更方便,因为第一种方式更加便捷。请参见我的回答中的进一步说明。 - Przemyslaw Remin