我正在尝试使用dplyr对包含同一组变量滞后的列以及(其中之一)其他组的滞后进行变异。编辑:抱歉,在第一版中,我在最后一秒重新排列了日期顺序,弄乱了顺序。
非常感谢!
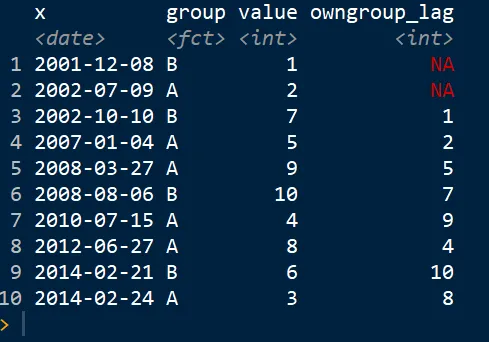
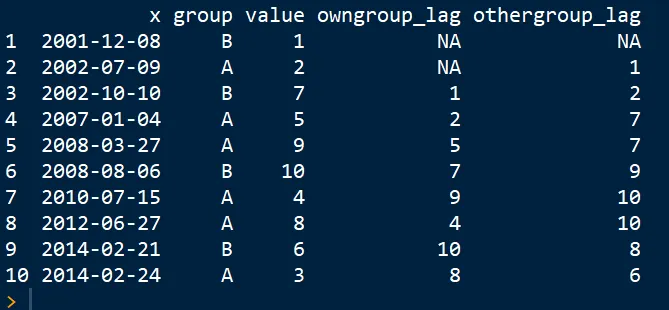 这是一个简单的代码示例:
这是一个简单的代码示例:
library(tidyverse)
set.seed(2)
df <-
data.frame(
x = sample(seq(as.Date('2000/01/01'), as.Date('2015/01/01'), by="day"), 10),
group = sample(c("A","B"),10,replace = T),
value = sample(1:10,size=10)
) %>% arrange(x)
df <- df %>%
group_by(group) %>%
mutate(own_lag = lag(value))
df %>% data.frame(other_lag = c(NA,1,2,7,7,9,10,10,8,6))
非常感谢!
other_lag是如何计算的? - mt1022findInterval会很有用。 - Rana Usman