如果不使用FLEX/BISON或任何类似的软件包,进行自顶向下解析的方法是首先编写一个可以解析输入并提供令牌的分词器。
基本上,您需要一个分词器,它提供getNextToken、peekNextToken和skipNextToken功能。
然后,您可以使用此结构逐步实现下降过程。
var input, currToken, pos;
var TOK_OPERATOR = 1;
var TOK_NUMBER = 2;
var TOK_EOF = 3;
function nextToken() {
var c, tok = {};
while(pos < input.length) {
c = input.charAt(pos++);
switch(c) {
case '+':
case '-':
case '*':
case '/':
case '(':
case ')':
tok.op = c;
tok.type = TOK_OPERATOR;
return tok;
case '0':
case '1':
case '2':
case '3':
case '4':
case '5':
case '6':
case '7':
case '8':
case '9':
tok.value = c;
tok.type = TOK_NUMBER;
return tok;
default:
throw "Unexpected character: " + c;
}
}
tok.type = TOK_EOF;
return tok;
}
function getNextToken() {
var ret;
if(currToken)
ret = currToken;
else
ret = nextToken();
currToken = undefined;
return ret;
}
function peekNextToken() {
if(!currToken)
currToken = nextToken();
return currToken;
}
function skipNextToken() {
if(!currToken)
currToken = nextToken();
currToken = undefined;
}
function parseString(str) {
input = str;
pos = 0;
return expression();
}
function expression() {
return additiveExpression();
}
function additiveExpression() {
var left = multiplicativeExpression();
var tok = peekNextToken();
while(tok.type == TOK_OPERATOR && (tok.op == '+' || tok.op == '-') ) {
skipNextToken();
var node = {};
node.op = tok.op;
node.left = left;
node.right = multiplicativeExpression();
left = node;
tok = peekNextToken();
}
return left;
}
function multiplicativeExpression() {
var left = primaryExpression();
var tok = peekNextToken();
while(tok.type == TOK_OPERATOR && (tok.op == '*' || tok.op == '/') ) {
skipNextToken();
var node = {};
node.op = tok.op;
node.left = left;
node.right = primaryExpression();
left = node;
tok = peekNextToken();
}
return left;
}
function primaryExpression() {
var tok = peekNextToken();
if(tok.type == TOK_NUMBER) {
skipNextToken();
node = {};
node.value = tok.value;
return node;
}
else
if(tok.type == TOK_OPERATOR && tok.op == '(') {
skipNextToken();
var node = expression();
tok = getNextToken();
if(tok.type != TOK_OPERATOR || tok.op != ')')
throw "Error ) expected";
return node
}
else
throw "Error " + tok + " not exptected";
}
正如您所看到的,您始终从请求最低特权操作开始,该操作需要其左右术语为下一个更高特权操作,以此类推。一元运算符的结构略有不同。有趣的是在遇到括号时的递归处理。
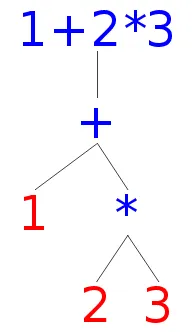
以下是一个演示页面,使用解析器并呈现解析树(代码已经准备好了...)
<html>
<head>
<title>tree</title>
<script src="parser.js"></script>
</head>
<body onload="testParser()">
<script>
function createTreeNode(x, y, val, color) {
var node = document.createElement("div");
node.style.position = "absolute";
node.style.left = "" + x;
node.style.top = "" + y;
node.style.border= "solid";
node.style.borderWidth= 1;
node.style.backgroundColor= color;
node.appendChild(document.createTextNode(val));
return node;
};
var yStep = 24;
var width = 800;
var height = 600;
var RED = "#ffc0c0";
var BLUE = "#c0c0ff";
container = document.createElement("div");
container.style.width = width;
container.style.height = height;
container.style.border = "solid";
document.body.appendChild(container);
var svgNS = "http://www.w3.org/2000/svg";
function renderLink(x1, y1, x2, y2)
{
var left = Math.min(x1,x2);
var top = Math.min(y1,y2);
var width = 1+Math.abs(x2-x1);
var height = 1+Math.abs(y2-y1);
var svg = document.createElementNS(svgNS, "svg");
svg.setAttribute("x", left);
svg.setAttribute("y", top);
svg.setAttribute("width", width );
svg.setAttribute("height", height );
var line = document.createElementNS(svgNS,"line");
line.setAttribute("x1", (x1 - left) );
line.setAttribute("x2", (x2 - left) );
line.setAttribute("y1", (y1 - top) );
line.setAttribute("y2", (y2 - top) );
line.setAttribute("stroke-width", "1");
line.setAttribute("stroke", "black");
svg.appendChild(line);
var div = document.createElement("div");
div.style.position = "absolute";
div.style.left = left;
div.style.top = top;
div.style.width = width;
div.style.height = height;
div.appendChild(svg);
container.appendChild(div);
}
function getHeight(dom) {
var h = dom.offsetHeight;
return h;
}
function getWidth(dom) {
var w = dom.offsetWidth;
return w;
}
function renderTree(x, y, node, width, height)
{
if(height < 1.5*yStep)
height = 1.5*yStep;
var val;
if(node.op) {
val = node.op;
color = BLUE;
}
else
if(node.value) {
val = node.value;
color = RED;
}
else
val = "?";
var dom = createTreeNode(x, y, val, color);
container.appendChild(dom);
var w = getWidth(dom);
var h = getHeight(dom);
var nx, ny;
var child;
if(node.left) {
nx = x - width/2;
ny = y+height;
var child = renderTree(nx, ny, node.left, width/2, height/2);
renderLink(x+w/2, y+h, nx+getWidth(child)/2, ny);
}
if(node.right) {
nx = x + width/2;
ny = y+height;
child = renderTree(nx, ny, node.right, width/2, height/2);
renderLink(x+w/2, y+h, nx+getWidth(child)/2, ny);
}
return dom;
}
var root;
function testParser()
{
var str = "1+2*5-5*(9+2)";
var exp = document.createElement("div");
exp.appendChild(document.createTextNode(str));
container.appendChild(exp);
var tree = parseString(str);
renderTree(width/2, 20, tree, width/2, 4*yStep);
}
</script>
</body>
</html>