我知道我来晚了,但我刚刚为此制作了一个库,我认为它可能会很有帮助。它非常简单,这就是为什么我认为你应该使用它的原因。它叫做TableIT。
基本用法
要使用它,首先请按照GitHub 页面上的下载说明进行操作。
然后导入它:
import TableIt
然后创建一个列表的列表,其中每个内部列表是一行:
table = [
[4, 3, "Hi"],
[2, 1, 808890312093],
[5, "Hi", "Bye"]
]
然后你所要做的就是将其打印出来:
TableIt.printTable(table)
这是你得到的输出:
+
| 4 | 3 | Hi |
| 2 | 1 | 808890312093 |
| 5 | Hi | Bye |
+
字段名称
如果您愿意,可以使用字段名称(如果您不使用字段名称,则无需设置useFieldNames=False,因为默认已设置为False):
TableIt.printTable(table, useFieldNames=True)
从中你将获得:
+
| 4 | 3 | Hi |
+
| 2 | 1 | 808890312093 |
| 5 | Hi | Bye |
+
还有其他用途,例如你可以这样做:
import TableIt
myList = [
["Name", "Email"],
["Richard", "richard@fakeemail.com"],
["Tasha", "tash@fakeemail.com"]
]
TableIt.print(myList, useFieldNames=True)
由此可见:
+-----------------------------------------------+
| Name | Email |
+-----------------------+-----------------------+
| Richard | richard@fakeemail.com |
| Tasha | tash@fakeemail.com |
+-----------------------------------------------+
或者你可以这样做:
import TableIt
myList = [
["", "a", "b"],
["x", "a + x", "a + b"],
["z", "a + z", "z + b"]
]
TableIt.printTable(myList, useFieldNames=True)
因此,您得到:
+
| | a | b |
+
| x | a + x | a + b |
| z | a + z | z + b |
+
颜色
您也可以使用颜色。
通过使用颜色选项(默认情况下设置为None)并指定RGB值来使用颜色。
使用上面的示例:
import TableIt
myList = [
["", "a", "b"],
["x", "a + x", "a + b"],
["z", "a + z", "z + b"]
]
TableIt.printTable(myList, useFieldNames=True, color=(26, 156, 171))
那么您将会得到:
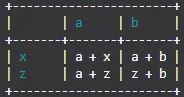
请注意,打印颜色可能对您无效,但它与其他打印彩色文本的库完全相同。我已经测试了每种颜色,没有任何问题,蓝色也不会出现错误,如果使用默认的34m ANSI转义序列(如果您不知道这是什么,也没关系),因为这一切都源于每种颜色都是RGB值而不是系统默认值。
更多信息
欲了解更多信息,请访问GitHub页面
{kind=link}