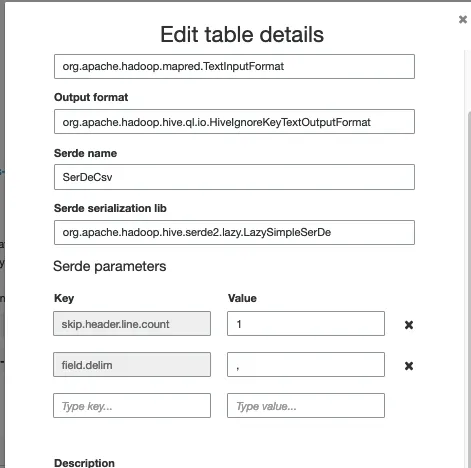
我正在尝试使用以下代码在Aws Athena上创建csv文件的外部表,但是TBLPROPERTIES ("skip.header.line.count"="1")这一行不起作用:它没有跳过csv文件的第一行(标题)。
CREATE EXTERNAL TABLE mytable
(
colA string,
colB int
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '\"',
'escapeChar' = '\\'
)
STORED AS TEXTFILE
LOCATION 's3://mybucket/mylocation/'
TBLPROPERTIES (
"skip.header.line.count"="1")
有什么建议吗?