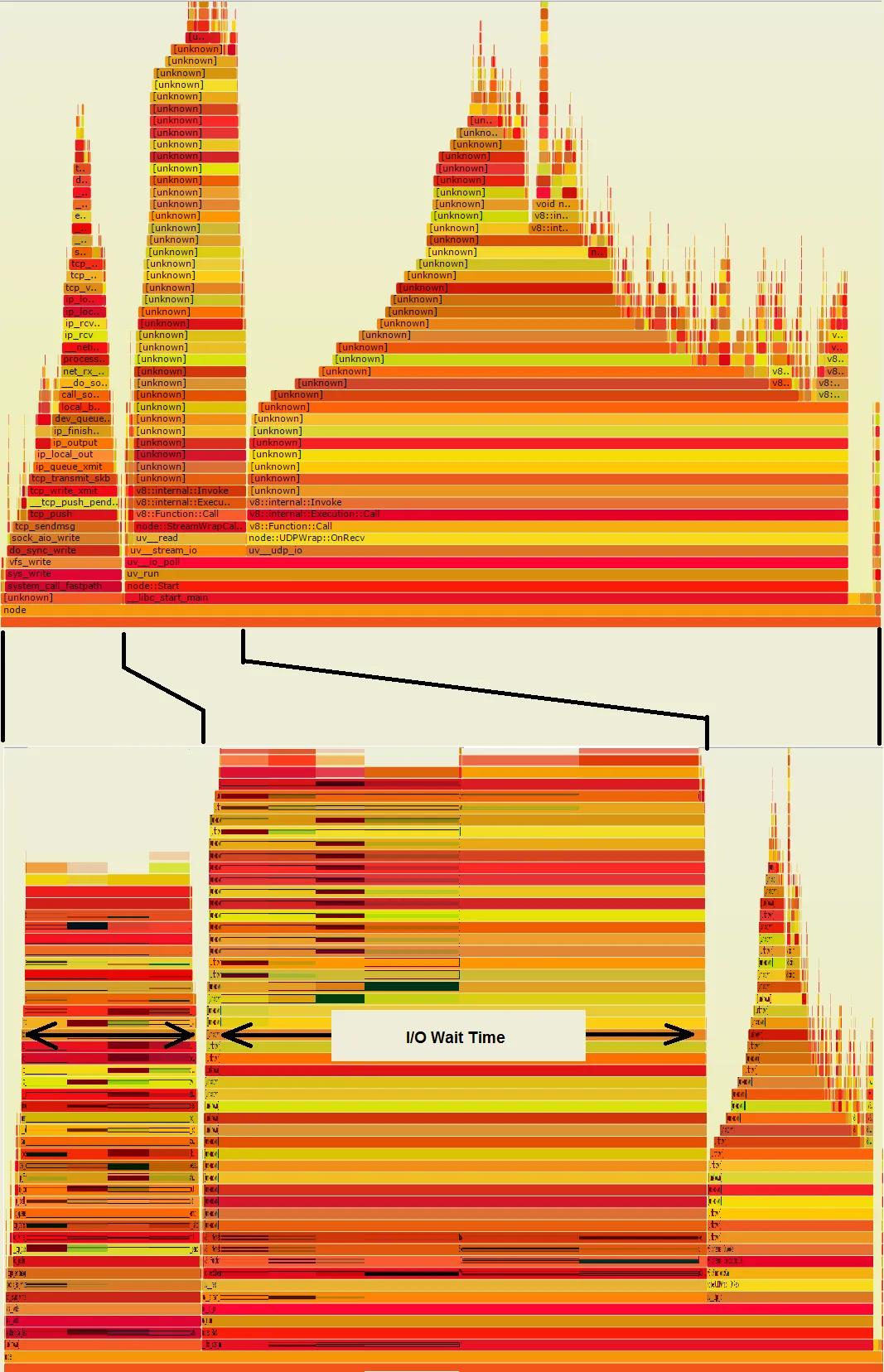
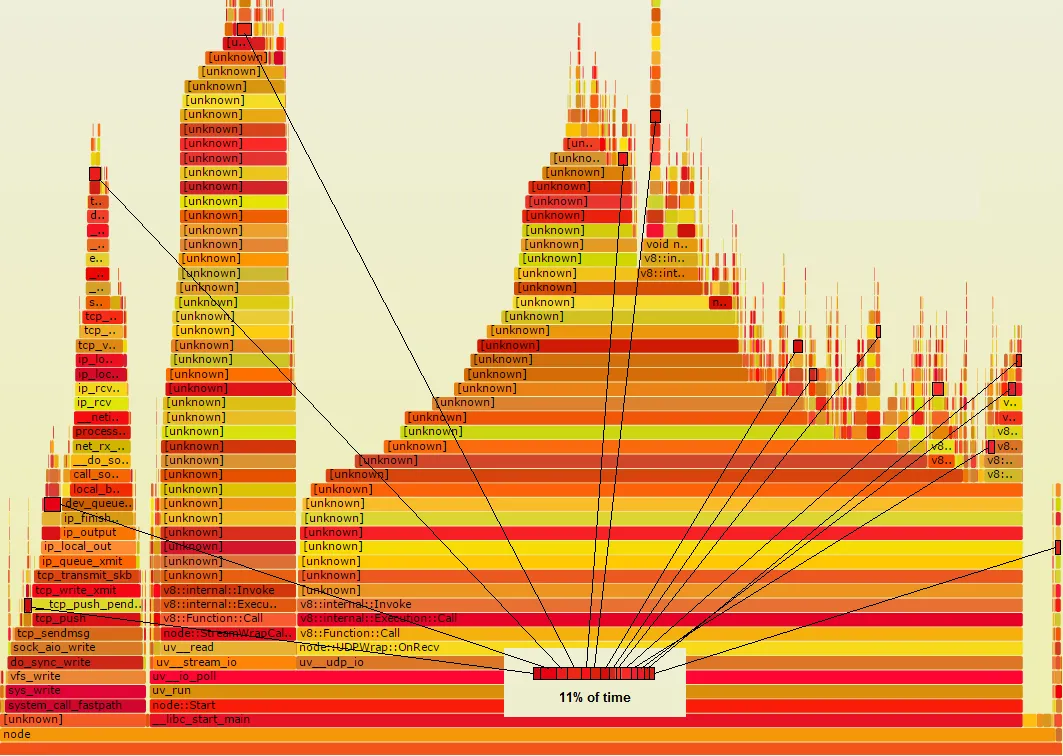
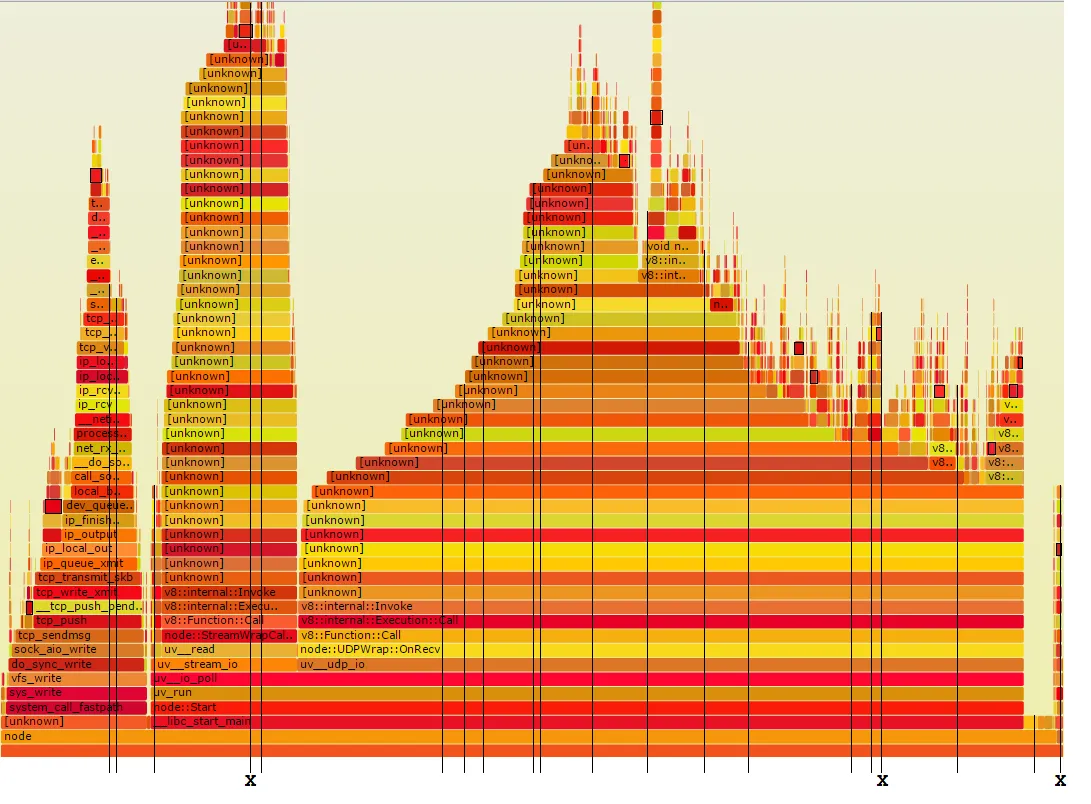
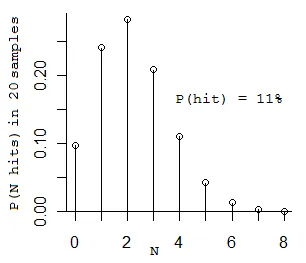
我尝试使用Linux perf_events来进行一些Node.js的性能分析,如Brendan Gregg在这里所述。工作流程如下:
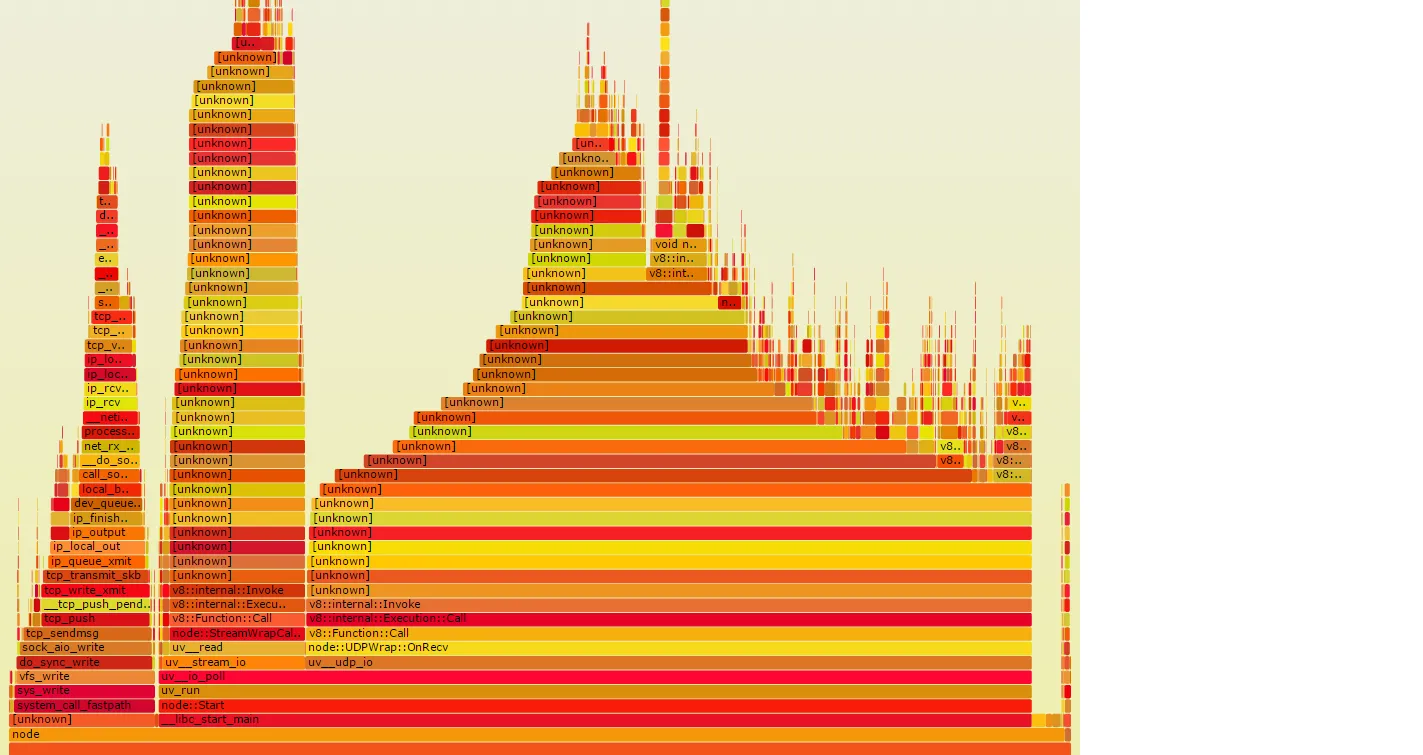 问题是有很多
问题是有很多
如何解决这个问题?
我正在使用CentOS 6.5 x64,并已经尝试了Node.js 0.11.13、0.11.14(预构建版本和编译版本),但都没有成功。
- 使用
--perf-basic-prof运行版本大于0.11.13的Node.js,它会创建/tmp/perf-(PID).map文件,其中写入了JavaScript符号映射。 - 使用
perf record -F 99 -p `pgrep -n node` -g -- sleep 30命令捕获堆栈信息。 - 使用此存储库中的
stackcollapse-perf.pl脚本来折叠堆栈信息。 - 使用
flamegraph.pl脚本生成svg火焰图。
问题是有很多[unknown]元素,我认为它们应该是我的Node.js函数调用。我假设整个过程在第3步失败了,在那里应该使用由带有--perf-basic-prof标志的node/v8执行生成的映射来折叠perf数据。在Node.js执行期间,会创建/tmp/perf-PID.map文件,并将其中一些映射写入其中。如何解决这个问题?
我正在使用CentOS 6.5 x64,并已经尝试了Node.js 0.11.13、0.11.14(预构建版本和编译版本),但都没有成功。