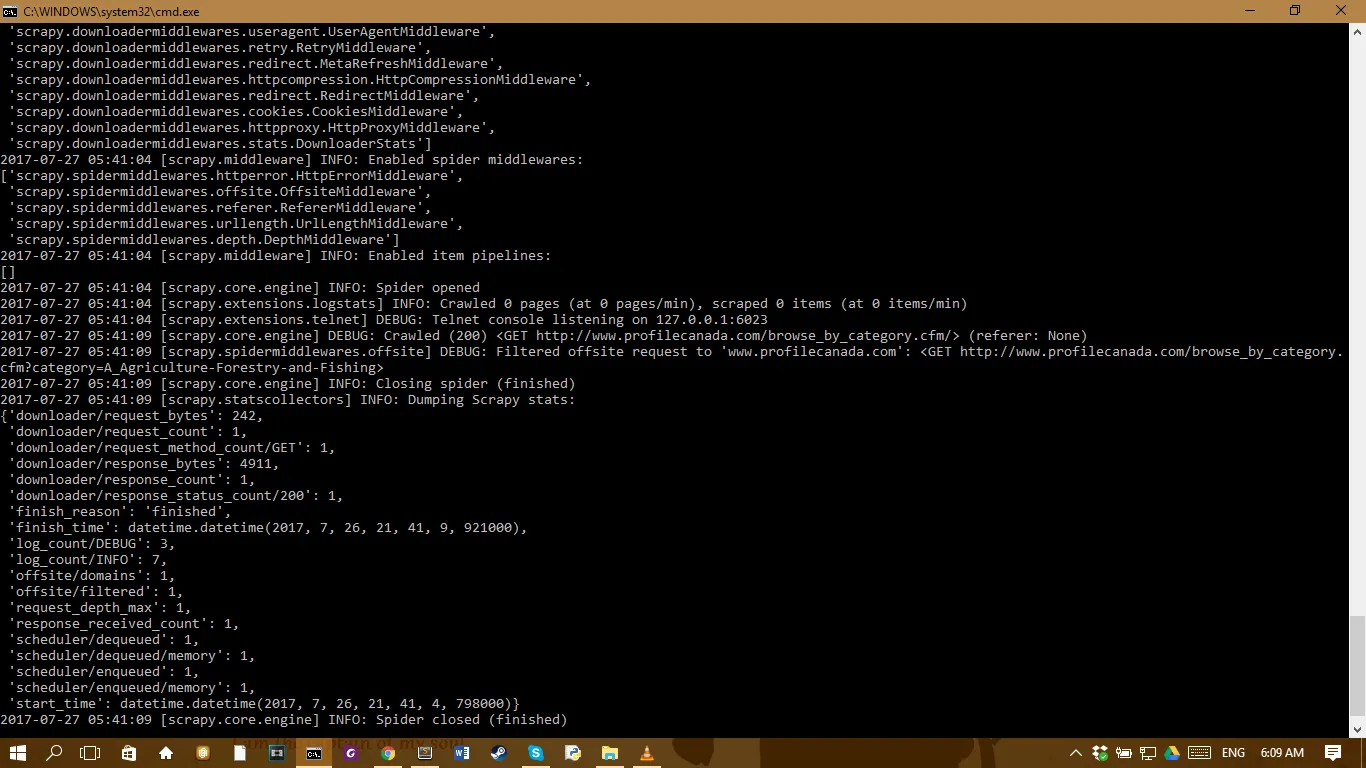
我是Scrapy和网络爬虫的新手,请不要生气。我正在尝试抓取profilecanada.com的数据。现在,当我运行下面的代码时,没有报错,但我认为它仍然没有抓取到数据。在我的代码中,我尝试从一个包含链接列表的页面开始。每个链接都会导致另一个包含链接列表的页面。从那个链接进入的页面包含了我需要提取并保存到json文件中的数据。总的来说,这就是所谓的“嵌套链接抓取”。我不知道实际上它被称为什么。请参见下面的图像,了解我运行蜘蛛程序时的结果。谢谢您提前的帮助。
import scrapy
class ProfilecanadaSpider(scrapy.Spider):
name = 'profilecanada'
allowed_domains = ['http://www.profilecanada.com']
start_urls = ['http://www.profilecanada.com/browse_by_category.cfm/']
def parse(self, response):
# urls in from start_url
category_list_urls = response.css('div.div_category_list > div.div_category_list_column > ul > li.li_category > a::attr(href)').extract()
# start_u = 'http://www.profilecanada.com/browse_by_category.cfm/'
# for each category of company
for url in category_list_urls:
url = url[3:]
url = response.urljoin(url)
return scrapy.Request(url=url, callback=self.profileCategoryPages)
def profileCategoryPages(self, response):
company_list_url = response.css('div.dv_en_block_name_frame > a::attr(href)').extract()
# for each company in the list
for url in company_list_url:
url = response.urljoin(url)
return scrapy.Request(url=url, callback=self.companyDetails)
def companyDetails(self, response):
return {
'company_name': response.css('span#name_frame::text').extract_first(),
'street_address': str(response.css('span#frame_addr::text').extract_first()),
'city': str(response.css('span#frame_city::text').extract_first()),
'region_or_province': str(response.css('span#frame_province::text').extract_first()),
'postal_code': str(response.css('span#frame_postal::text').extract_first()),
'country': str(response.css('div.type6_GM > div > div::text')[-1].extract())[2:],
'phone_number': str(response.css('span#frame_phone::text').extract_first()),
'fax_number': str(response.css('span#frame_fax::text').extract_first()),
'email': str(response.css('span#frame_email::text').extract_first()),
'website': str(response.css('span#frame_website > a::attr(href)').extract_first()),
}
CMD中的图像结果: 当我运行蜘蛛程序时在CMD中的结果
{kind=link}