我在Python中有一个Unicode字符串,我想要去掉所有的重音符号(变音符号)。
我在网上找到了一种优雅的方法(在Java中):
- 将Unicode字符串转换为其长规范形式(具有字母和变音符号的单独字符)
- 删除其Unicode类型为“变音符号”的所有字符。
我是否需要安装类库,如pyICU,还是只能用Python标准库? 而且对于Python 3呢?
重要说明:我希望避免使用显式映射从带重音符号的字符到它们的非带重音符号的对应项。
我在Python中有一个Unicode字符串,我想要去掉所有的重音符号(变音符号)。
我在网上找到了一种优雅的方法(在Java中):
我是否需要安装类库,如pyICU,还是只能用Python标准库? 而且对于Python 3呢?
重要说明:我希望避免使用显式映射从带重音符号的字符到它们的非带重音符号的对应项。
示例:
>>> from unidecode import unidecode
>>> unidecode('kožušček')
'kozuscek'
>>> unidecode('北亰')
'Bei Jing '
>>> unidecode('François')
'Francois'
import unicodedata
def strip_accents(s):
return ''.join(c for c in unicodedata.normalize('NFD', s)
if unicodedata.category(c) != 'Mn')
这也适用于希腊字母:
>>> strip_accents(u"A \u00c0 \u0394 \u038E")
u'A A \u0394 \u03a5'
>>>
字符类别 "Mn" 代表非间距符号,与MiniQuark的答案中的unicodedata.combining类似(我没有想到unicodedata.combining,但它可能是更好的解决方案,因为它更明确)。
请记住,这些操作可能会显着改变文本的含义。重音符号、Umlaut等不是“装饰品”。
unicodedata.name 解析的技巧,要么就得动用类似表格——无论如何你都需要用到希腊字母(Α 只是 "GREEK CAPITAL LETTER ALPHA")。 - alexis我刚在网上找到了这个答案:
import unicodedata
def remove_accents(input_str):
nfkd_form = unicodedata.normalize('NFKD', input_str)
only_ascii = nfkd_form.encode('ASCII', 'ignore')
return only_ascii
它很好用(例如对于法语),但我认为第二步(去除重音符号)可以更好地处理,而不是放弃非ASCII字符,因为这将对一些语言(例如希腊语)造成失败。最好的解决方案可能是显式删除标记为变音符号的Unicode字符。
编辑:这样做就可以了:
import unicodedata
def remove_accents(input_str):
nfkd_form = unicodedata.normalize('NFKD', input_str)
return u"".join([c for c in nfkd_form if not unicodedata.combining(c)])
unicodedata.combining(c)将返回true,如果字符c可以与前一个字符合并,这主要是指它是一个变音符。
编辑2: remove_accents需要一个unicode字符串而不是字节字符串。如果你有一个字节字符串,那么你必须像这样解码成一个unicode字符串:
encoding = "utf-8" # or iso-8859-15, or cp1252, or whatever encoding you use
byte_string = b"café" # or simply "café" before python 3.
unicode_string = byte_string.decode(encoding)
nkfd_form = unicodedata.normalize('NFKD', unicode(input_str, 'utf8'))。 - Jabba- rbpdef remove_accents(input_str): ... nkfd_form = unicodedata.normalize('NFKD', unicode(input_str)) ... return u"".join([c for c in nkfd_form if not unicodedata.combining(c)]) ... remove_accents('é') 跟踪最近的调用(最近的一次调用在最后) 文件“<stdin>”,第1行,in <module> 文件“<stdin>”,第2行,in remove_accents UnicodeDecodeError: 'ascii'编解码器无法解码位置0处的字节0xc3:序数不在范围内(128)
remove_accents传递一个Unicode字符串,而不是普通字符串(例如使用u"é"代替"é")。你向remove_accents传递了一个普通字符串,因此在尝试将其转换为Unicode字符串时,使用了默认的ascii编码。该编码不支持任何值>127的字节。当您在shell中键入“é”时,您的操作系统对其进行了编码,可能使用了UTF-8或某些Windows代码页编码,并且其中包含了>127的字节。我将更改我的函数以删除对Unicode的转换:如果传递了非Unicode字符串,则会更清楚地出现错误。 - MiniQuark- rbpremove_accents(unicode('é'))
实际上,我正在处理兼容 Python 2.6、2.7 和 3.4 的项目,我需要从用户输入中创建 ID。
得益于您,我已经创建了这个非常有效的函数。
import re
import unicodedata
def strip_accents(text):
"""
Strip accents from input String.
:param text: The input string.
:type text: String.
:returns: The processed String.
:rtype: String.
"""
try:
text = unicode(text, 'utf-8')
except (TypeError, NameError): # unicode is a default on python 3
pass
text = unicodedata.normalize('NFD', text)
text = text.encode('ascii', 'ignore')
text = text.decode("utf-8")
return str(text)
def text_to_id(text):
"""
Convert input text to id.
:param text: The input string.
:type text: String.
:returns: The processed String.
:rtype: String.
"""
text = strip_accents(text.lower())
text = re.sub('[ ]+', '_', text)
text = re.sub('[^0-9a-zA-Z_-]', '', text)
return text
结果:
text_to_id("Montréal, über, 12.89, Mère, Françoise, noël, 889")
>>> 'montreal_uber_1289_mere_francoise_noel_889'
text = unicode(text, 'utf-8')еӨ„дә§з”ҹй”ҷиҜҜгҖӮи§ЈеҶіж–№жі•жҳҜж·»еҠ except TypeError: passгҖӮ - Daniel ReisM 是大写的,那么输出中的 M 也是大写的?输入字符串 "Montréal" 变成输出字符串 "Montreal"。 - Samuel Muldoon这个处理不仅包括重音符号,还包括“笔画”(如ø等):
import unicodedata as ud
def rmdiacritics(char):
'''
Return the base character of char, by "removing" any
diacritics like accents or curls and strokes and the like.
'''
desc = ud.name(char)
cutoff = desc.find(' WITH ')
if cutoff != -1:
desc = desc[:cutoff]
try:
char = ud.lookup(desc)
except KeyError:
pass # removing "WITH ..." produced an invalid name
return char
这是我所能想到的最优雅的方式(如Alexis在此页面的评论中提到),但实际上我并不认为它非常优雅。 实际上,正如评论中指出的那样,这更像是一种hack,因为Unicode名称只是名称,它们并不能保证一致性或其他任何东西。
仍然有一些特殊符号无法处理,例如翻转和倒置字母,因为它们的 Unicode 名称不包含“WITH”。不过这取决于你想做什么。有时,我需要去除重音以实现按字典排序。
根据评论中的建议进行修改(处理查找错误、Python-3 代码)。
unicode函数调用吗?我认为使用更紧凑的正则表达式代替find可以避免上面评论中提到的所有麻烦,并且记忆化可以在关键代码路径时提高性能。 - matanster依我看,建议的解决方案不应该被接受为答案。原问题要求去除口音,所以正确的答案应该只做到这一点,而不是加上其他未指明的更改。
只需观察这段代码的结果,即被接受的答案。在那里,我已将"Málaga"更改为"Málagueña:
accented_string = u'Málagueña'
# accented_string is of type 'unicode'
import unidecode
unaccented_string = unidecode.unidecode(accented_string)
# unaccented_string contains 'Malaguena'and is of type 'str'
还有一个额外的更改(ñ -> n),并未在OQ中请求。
一个简单的函数,以小写形式执行所需任务:
def f_remove_accents(old):
"""
Removes common accent characters, lower form.
Uses: regex.
"""
new = old.lower()
new = re.sub(r'[àáâãäå]', 'a', new)
new = re.sub(r'[èéêë]', 'e', new)
new = re.sub(r'[ìíîï]', 'i', new)
new = re.sub(r'[òóôõö]', 'o', new)
new = re.sub(r'[ùúûü]', 'u', new)
return new
gensim.utils.deaccent(text)来自Gensim - 为人类设计的主题建模工具:
'Sef chomutovskych komunistu dostal postou bily prasek'
'ł'转换为'',而不是'l')。deaccent 仍然返回 ł 而不是 l。 - lcieslakNumPy和SciPy来去除重音符号。 - Nuno André回复@MiniQuark的答案:
我试图读取一个包含重音符号的半法语csv文件,其中还包含一些最终将变为整数和浮点数的字符串。
作为测试,我创建了一个名为test.txt的文件,内容如下:
Montréal, über, 12.89, Mère, Françoise, noël, 889
我必须包含第2行和第3行才能让它正常工作(这是我在Python票据中找到的),并且结合了@Jabba的意见:
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
import csv
import unicodedata
def remove_accents(input_str):
nkfd_form = unicodedata.normalize('NFKD', unicode(input_str))
return u"".join([c for c in nkfd_form if not unicodedata.combining(c)])
with open('test.txt') as f:
read = csv.reader(f)
for row in read:
for element in row:
print remove_accents(element)
结果:
Montreal
uber
12.89
Mere
Francoise
noel
889
remove_accents旨在从Unicode字符串中删除重音符号。如果传递的是字节字符串,它会尝试使用unicode(input_str)将其转换为Unicode字符串。这使用Python的默认编码,即"ascii"。由于您的文件已使用UTF-8编码,因此这将失败。第2行和第3行更改了Python的默认编码为UTF-8,因此它可以正常工作,正如您所发现的那样。另一个选项是将Unicode字符串传递给remove_accents:删除第2行和第3行,最后一行将element替换为element.decode("utf-8")。我测试过了:它可以正常工作。我会更新我的答案,以使这更清晰。 - MiniQuarkiso-8859-1编码的,但不幸的是我无法使用这个函数来处理它!) - aseagramreload(sys); sys.setdefaultencoding("utf-8") 是一个有争议的黑客技巧,有时会建议在Windows系统中使用;有关详细信息,请参见https://dev59.com/XV4b5IYBdhLWcg3wzUja。 - PM 2Ring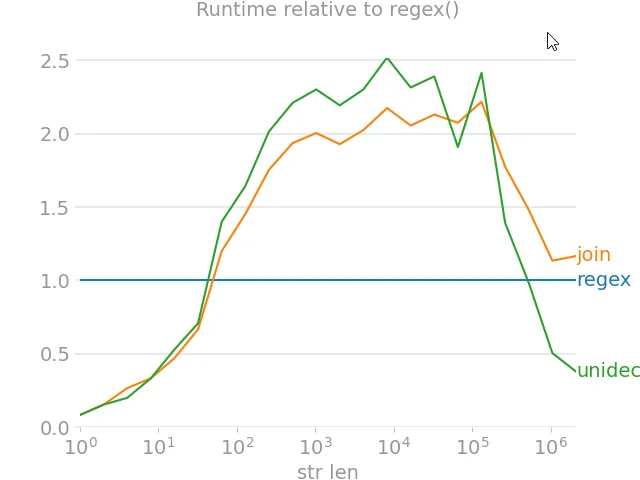
import unicodedata
from random import choice
import perfplot
import regex
import text_unidecode
def remove_accent_chars_regex(x: str):
return regex.sub(r'\p{Mn}', '', unicodedata.normalize('NFKD', x))
def remove_accent_chars_join(x: str):
# answer by MiniQuark
# https://dev59.com/8HRB5IYBdhLWcg3wxZ7Y#517974
return u"".join([c for c in unicodedata.normalize('NFKD', x) if not unicodedata.combining(c)])
perfplot.show(
setup=lambda n: ''.join([choice('Málaga François Phút Hơn 中文') for i in range(n)]),
kernels=[
remove_accent_chars_regex,
remove_accent_chars_join,
text_unidecode.unidecode,
],
labels=['regex', 'join', 'unidecode'],
n_range=[2 ** k for k in range(22)],
equality_check=None, relative_to=0, xlabel='str len'
)
unidecode实际上可以处理中文字符。而且三个测试用例中都没有出现令人发笑的“FranASSois”。 - mike rodentfrom unicodedata import combining, normalize
LATIN = "ä æ ǽ đ ð ƒ ħ ı ł ø ǿ ö œ ß ŧ ü "
ASCII = "ae ae ae d d f h i l o o oe oe ss t ue"
def remove_diacritics(s, outliers=str.maketrans(dict(zip(LATIN.split(), ASCII.split())))):
return "".join(c for c in normalize("NFD", s.lower().translate(outliers)) if not combining(c))
sorted(['cote', 'coteau', "crottez", 'crotté', 'côte', 'côté'], key=remove_diacritics)
输出:
['cote', 'côte', 'côté', 'coteau', 'crotté', 'crottez']
remove_diacritics()函数与我提供的string_to_pairs()函数感兴趣。请点击其他地方。
为了确保行为符合您的需求,请查看下面的句子:
examples = [
("hello, world", "hello, world"),
("42", "42"),
("你好,世界", "你好,世界"),
(
"Dès Noël, où un zéphyr haï me vêt de glaçons würmiens, je dîne d’exquis rôtis de bœuf au kir, à l’aÿ d’âge mûr, &cætera.",
"des noel, ou un zephyr hai me vet de glacons wuermiens, je dine d’exquis rotis de boeuf au kir, a l’ay d’age mur, &caetera.",
),
(
"Falsches Üben von Xylophonmusik quält jeden größeren Zwerg.",
"falsches ueben von xylophonmusik quaelt jeden groesseren zwerg.",
),
(
"Љубазни фењерџија чађавог лица хоће да ми покаже штос.",
"љубазни фењерџија чађавог лица хоће да ми покаже штос.",
),
(
"Ljubazni fenjerdžija čađavog lica hoće da mi pokaže štos.",
"ljubazni fenjerdzija cadavog lica hoce da mi pokaze stos.",
),
(
"Quizdeltagerne spiste jordbær med fløde, mens cirkusklovnen Walther spillede på xylofon.",
"quizdeltagerne spiste jordbaer med flode, mens cirkusklovnen walther spillede pa xylofon.",
),
(
"Kæmi ný öxi hér ykist þjófum nú bæði víl og ádrepa.",
"kaemi ny oexi her ykist þjofum nu baedi vil og adrepa.",
),
(
"Glāžšķūņa rūķīši dzērumā čiepj Baha koncertflīģeļu vākus.",
"glazskuna rukisi dzeruma ciepj baha koncertfligelu vakus.",
)
]
for (given, expected) in examples:
assert remove_diacritics(given) == expected
LATIN = "ä æ ǽ đ ð ƒ ħ ı ł ø ǿ ö œ ß ŧ ü Ä Æ Ǽ Đ Ð Ƒ Ħ I Ł Ø Ǿ Ö Œ ẞ Ŧ Ü "
ASCII = "ae ae ae d d f h i l o o oe oe ss t ue AE AE AE D D F H I L O O OE OE SS T UE"
def remove_diacritics(s, outliers=str.maketrans(dict(zip(LATIN.split(), ASCII.split())))):
return "".join(c for c in normalize("NFD", s.translate(outliers)) if not combining(c))
ValueError: string keys in translate table must be of length 1。这个限制在Python文档中明确说明:https://docs.python.org/3/library/stdtypes.html#str.maketrans。也许你只是在Python 2上进行了测试? - John J. CamilleriLATIN字符串中有一个“SS”。我已经用“ẞ”即大写锐音符S替换了它。谢谢! - AristideLATIN 字符串中有一个 "SS"。我已经用 "ẞ" 替换了它,即拉丁大写字母尖S。谢谢! - undefined
'François'被映射为'Francois',正如您所期望的那样。 - Mark Amery°替换为deg,它不仅仅是去除重音符号。 - Eric Duminil