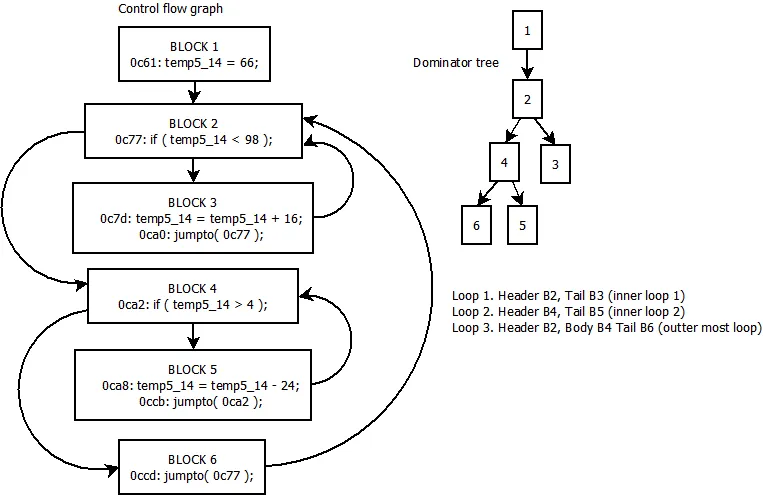
结构化是反编译开发中最难的部分(至少对于高级语言而言)。这是一个相当简单的算法,所以它是一个很好的起点,但如果你正在开发一个真正的反编译器,你可能想使用更好的算法或者自己编写算法。
除此之外,关于如何使用do-while循环而不是while循环的实际问题,答案已经在你链接到的页面上回答过了。
每个循环都可以用“do-while”语句来描述。
“while”循环(前测试循环)是“do-while”循环的一种特殊情况,其中底部条件始终为真,并且循环的第一条语句是一个“if”,用于跳出循环。
假设你有这样的东西:
beforeloop
while(foo) {
stmt1
stmt2
}
afterloop
它将被编译成类似以下的内容。
beforeloop
LOOPBEGIN:
if !foo goto LOOPEND
stmt1
stmt2
goto LOOPBEGIN
LOOPEND:
afterloop
反编译算法将其转换为:
beforeloop
do {
if (!foo) {break}
stmt1
stmt2
} while (true)
afterloop
我希望这能让问题得到解决。如果不能,可以随意提出其他问题。
编辑:示例2,展示如何折叠具有相同入口点的多个循环。
for(;;) { while(foo) {} while(bar){} }
首先,for(;;) 相当于 while(true),因此我将使用以下(伪)代码
while(true) { while(foo) {stmt1} while(bar){stmt2} }
让外层循环称为循环A,内层循环称为循环B和C。这将编译成类似于以下伪汇编代码的东西。
LOOP_A_BEGIN:
LOOP_B_BEGIN:
if !foo goto LOOP_B_END
stmt1
goto LOOP_B_BEGIN
LOOP_B_END:
LOOP_C_BEGIN:
if !bar goto LOOP_C_END
stmt2
goto LOOP_C_BEGIN
LOOP_C_END:
goto LOOP_A_BEGIN
当然,标签不会占用任何空间。因此,如果折叠相同的标签,则变为:
POINT1:
if !foo goto POINT2
stmt1
goto POINT1
POINT2:
if !bar goto POINT3
stmt2
goto POINT2
POINT3
goto POINT1
现在,有两个带有反向边的点 - 点1和点2。我们可以为每个节点创建一个循环,并使用标记的中断以增强清晰度。转换并不是非常直接,因为你需要稍微修改if语句,但这仍然相当容易。
LOOP1: while(true) {
IF1: if (!foo) {
break IF1;
}
else {
stmt1;
continue LOOP1;
}
LOOP2: while(true) {
if (!bar) {
break LOOP2;
}
else {
stmt2;
continue LOOP2;
}
}
continue LOOP1;
}
现在,同样的代码已经简化,去掉了不必要的标签。
while(true) {
if (!foo) {
}
else {
stmt1;
continue;
}
while(true) {
if (!bar) {
break;
}
else {
stmt2;
}
}
}
现在,if语句已经简化。
while(true) {
if (foo) {
stmt1;
continue;
}
while(true) {
if (!bar) {
break;
}
stmt2;
}
}
最后,您可以将 while(true) if(!x) 转换应用于内部循环。由于是合并循环的结果,外部循环无法像这样进行转换,因为它不是简单的 while(cond) 循环。
while(true) {
if (foo) {
stmt1;
continue;
}
while(bar) {
stmt2;
}
}
希望这能展示如何通过将多个循环合并为一个循环来处理具有相同入口点的情况,但可能需要重新排列一些if语句。