自Java 8(像其他语言一样)中的
迄今为止,我已经阅读了这个示例,但由于我不是专业的Java编码人员,我很难掌握这个概念。
以下是其内容:
各种字符串重复的策略都被考虑过,但现在实施的策略遵循以下方法:每当垃圾收集器访问String对象时,它会注意到char数组。它获取它们的哈希值并将其存储在弱引用数组旁边。只要它找到另一个具有相同哈希代码的字符串,它就逐个比较它们。如果它们也匹配,一个字符串将被修改并指向第二个字符串的char数组。那么第一个char数组就不再被引用,可以进行垃圾回收。
当然,整个过程会带来一些额外开销,但由严格的限制控制。例如,如果一段时间内未发现字符串具有重复项,则不再进行检查。 我的第一个问题: 由于它最近添加到Java 8更新20中,因此仍缺乏有关此主题的资源,是否有人可以在此处分享有关如何帮助减少
只要它找到另一个具有相同哈希代码的字符串,就会逐个比较它们 我的第二个问题:如果两个字符串的哈希码相同,则这两个字符串已经相同,那么一旦发现两个字符串具有相同的哈希码,为什么还要逐个比较它们的字符?请保留HTML标记。
String占用大量内存,因为每个字符占用两个字节,因此引入了一个名为String Deduplication的新功能,它利用char数组是字符串内部和final的事实,因此JVM可以与它们搞混。迄今为止,我已经阅读了这个示例,但由于我不是专业的Java编码人员,我很难掌握这个概念。
以下是其内容:
各种字符串重复的策略都被考虑过,但现在实施的策略遵循以下方法:每当垃圾收集器访问String对象时,它会注意到char数组。它获取它们的哈希值并将其存储在弱引用数组旁边。只要它找到另一个具有相同哈希代码的字符串,它就逐个比较它们。如果它们也匹配,一个字符串将被修改并指向第二个字符串的char数组。那么第一个char数组就不再被引用,可以进行垃圾回收。
当然,整个过程会带来一些额外开销,但由严格的限制控制。例如,如果一段时间内未发现字符串具有重复项,则不再进行检查。 我的第一个问题: 由于它最近添加到Java 8更新20中,因此仍缺乏有关此主题的资源,是否有人可以在此处分享有关如何帮助减少
String在Java中消耗的内存的实际示例?
编辑:
以上链接说:只要它找到另一个具有相同哈希代码的字符串,就会逐个比较它们 我的第二个问题:如果两个字符串的哈希码相同,则这两个字符串已经相同,那么一旦发现两个字符串具有相同的哈希码,为什么还要逐个比较它们的字符?请保留HTML标记。
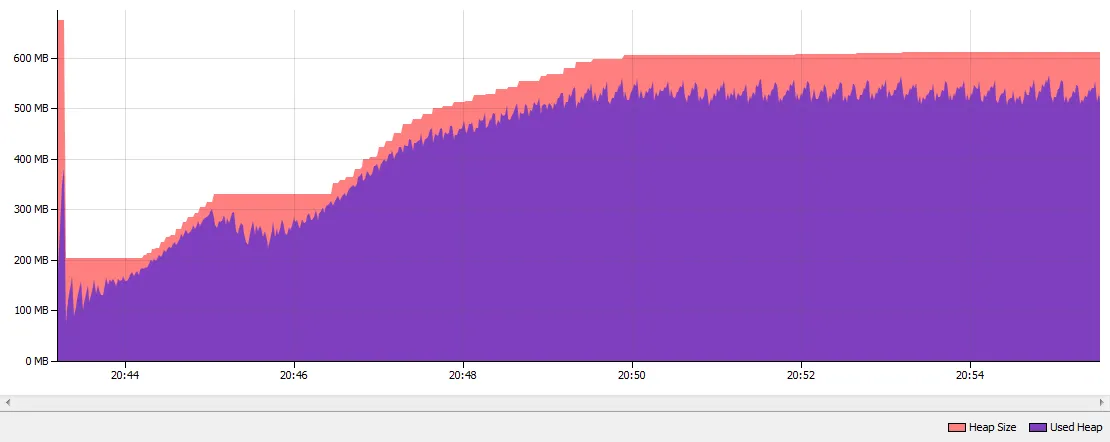
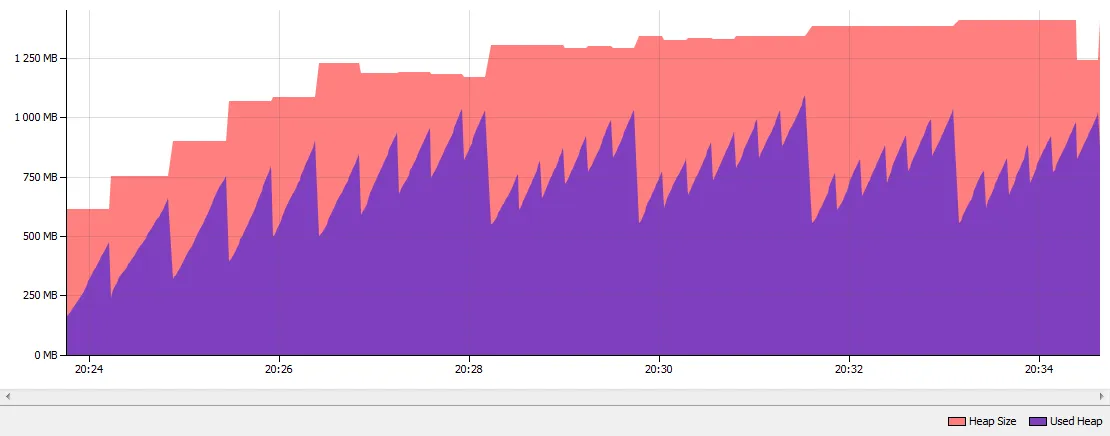 Java 8 G1 GC with String Deduplication
Java 8 G1 GC with String Deduplication
String,即65536²¹⁴⁷⁴⁸³⁶⁴⁸ == practically infinite。换句话说,具有相同的哈希码并不保证这些String是相等的,你需要检查它们是否相等。相反地,有不同的哈希码则意味着这些String不相等。 - Holgerchar是一个 16 位的值,所以它允许有2¹⁶ == 65536种组合。一个String是一个有着int长度的序列,因此它最多可以有2³¹个字符(2³¹而不是2³²是因为 Java 中的int是有符号的,但是String的大小是正数),所以最大的String长度是2³¹ == 2147483648(理论上,实际限制会略小一些)。因此,一个String最多可以组合达到 2147483648 个字符,每个字符可以有 65536 种可能的组合方式,这使得总共有65536²¹⁴⁷⁴⁸³⁶⁴⁸种组合方式(实际上可能会稍微多一些,因为一个String可能也会更短)。 - Holger