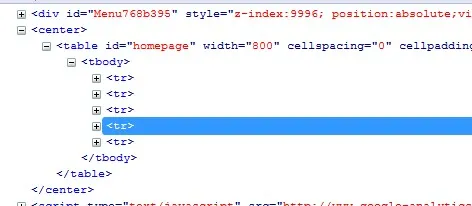
我试着提取上表中列出的所有五行数据。
我使用Ruby hpricot库通过xpath表达式来提取表格行。
在我的示例中,我使用的xpath表达式是/html/body/center/table/tr。请注意,我从表达式中删除了tbody标签,这通常可以成功提取。
奇怪的是,我得到了结果中的前三行,但最后两行缺失。我真的不知道发生了什么。
编辑:代码没有任何魔法,只是根据请求附加它。
require 'open-uri'
require 'hpricot'
faculty = Hpricot(open("http://www.utm.utoronto.ca/7800.0.html"))
(faculty/"/html/body/center/table/tr").each do |text|
puts text.to_s
end