您正在使用与Unicode完全相反的编码方式。控制台采用8位代码页,西方计算机上的默认代码页是
代码页437,它与旧IBM PC字符ROM的字符集匹配,并且是大多数传统DOS程序所期望的代码页。第一组字符代码,即0到8号代码如下图所示:
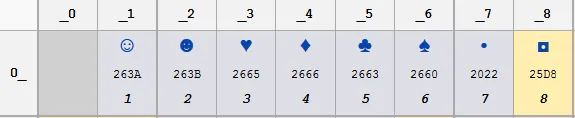
请注意,代码0x02对应的笑脸就是您在控制台上看到的那个。您可以在此
Wikipedia文章中查看其余的字形。8位字符编码的一个大问题是有太多这样的编码方式。记事本使用的是
不同的代码页来读取您的文件。在西欧和美洲的计算机上,默认代码页为
Windows-1252。该页面没有任何控制字符的字形,这就是为什么您在记事本中没有看到笑脸的原因。
处理代码页是一个很大的头痛。这就是为什么Unicode被发明的原因。
将控制台切换到Unicode代码页是可能的。但是它仍然必须是一个8位编码,这是支持输出重定向的控制台程序的另一个传统遗留问题。因此,正确的选择是utf-8。您可以在启动程序之前通过键入
chcp 65001来从控制台本身进行切换。或者您可以在代码中执行此操作,调用
SetConsoleOutputCP(CP_UTF8);。
还有一个不幸的细节需要注意,您还需要更改用于控制台的字体。默认字体是TERMINAL,它是一种旨在显示IBM PC字形但对Unicode一无所知的传统字体。使用系统菜单进行切换(按Alt + Space,属性),可供选择的不多,但Consolas或Lucinda Console都是合适的选择。
现在,您可以显示Unicode了,这是Remy介绍的另一个故事。