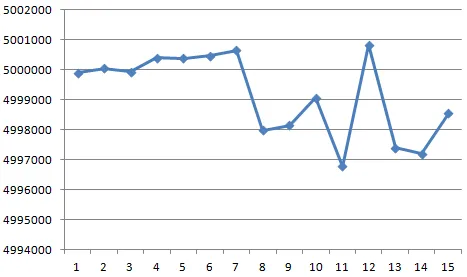
我进行了这样的实验——从C和C#中生成1000万个随机数,然后统计每个随机整数中15位比特中设置的次数。(我选择15位,因为C仅支持随机整数到0x7fff)。
我得到了这个结果:
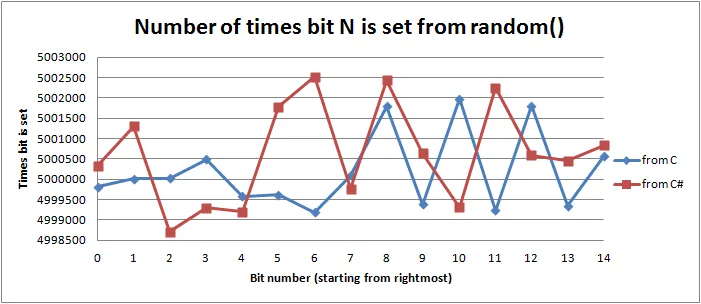
我有两个问题:
为什么有3个最可能的比特?在
C情况下,比特8,10,12最有可能。而在C#情况下,比特6,8,11最为常见。此外,似乎C#最有可能的比特位置与C最有可能的比特位置相比多了2个位置。这是为什么?因为C#使用其他RAND_MAX常量吗?
C的测试代码:void accumulateResults(int random, int bitSet[15]) {
int i;
int isBitSet;
for (i=0; i < 15; i++) {
isBitSet = ((random & (1<<i)) != 0);
bitSet[i] += isBitSet;
}
}
int main() {
int i;
int bitSet[15] = {0};
int times = 10000000;
srand(0);
for (i=0; i < times; i++) {
accumulateResults(rand(), bitSet);
}
for (i=0; i < 15; i++) {
printf("%d : %d\n", i , bitSet[i]);
}
system("pause");
return 0;
}
以下是 C# 的测试代码:
static void accumulateResults(int random, int[] bitSet)
{
int i;
int isBitSet;
for (i = 0; i < 15; i++)
{
isBitSet = ((random & (1 << i)) != 0) ? 1 : 0;
bitSet[i] += isBitSet;
}
}
static void Main(string[] args)
{
int i;
int[] bitSet = new int[15];
int times = 10000000;
Random r = new Random();
for (i = 0; i < times; i++)
{
accumulateResults(r.Next(), bitSet);
}
for (i = 0; i < 15; i++)
{
Console.WriteLine("{0} : {1}", i, bitSet[i]);
}
Console.ReadKey();
}
非常感谢!! 顺便说一下,操作系统是Windows 7,64位结构以及Visual Studio 2010。
编辑
非常感谢@David Heffernan。我犯了几个错误:
- C和C#程序中的种子不同(C使用零,而C#使用当前时间)。
- 我没有尝试使用不同的
Times变量值进行实验,以研究结果的重现性。
当分析第一个比特设置的概率如何取决于调用random()的次数时,这就是我得到的结果:
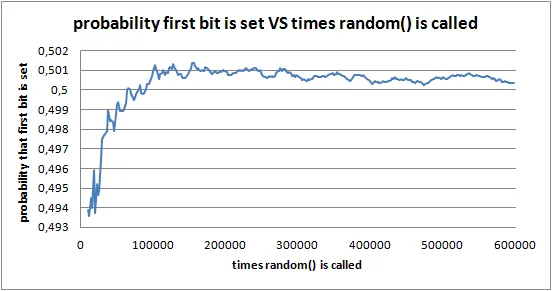
因此,正如许多人注意到的那样 - 结果不可重复且不应被认真对待。
(除非作为某种形式的确认,即C / C# PRNG已足够好 :-) )。