在微服务架构的背景下,消息驱动、异步、基于事件的设计似乎越来越受欢迎(参见此处和此处以及反应式宣言-消息驱动特性),而不是同步的(可能是基于REST的)机制。
在这个背景下,假设一个过度简化的订单系统如下所示:
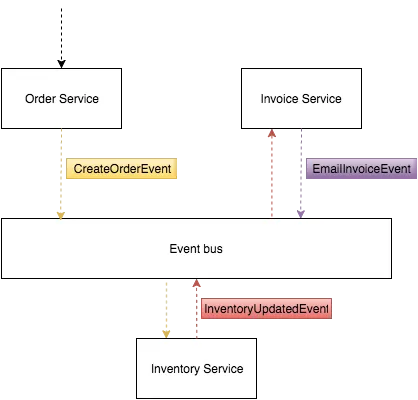
以及以下的消息流:
- 从某个来源(Web / 移动等)下单
- 订单服务接受订单并发布
CreateOrderEvent - 库存服务对
CreateOrderEvent作出反应,进行一些库存操作,并在完成后发布InventoryUpdatedEvent - 然后发票服务对
InventoryUpdatedEvent做出反应,发送发票并发布EmailInvoiceEvent
所有服务都正常运行,我们愉快地处理订单...大家都很开心。 然后,库存服务因某种原因停止工作。
假设事件总线上的事件以“非阻塞”的方式流动。也就是说,如果消息发布到中央主题并且没有服务从中读取,则消息不会在队列中堆积(我试图传达的是一个事件总线,即使事件发布到总线上,它也会直接流过去而不会排队 - 在这一点上忽略使用的消息平台/技术)。这意味着,如果库存服务停机5分钟,那么在此期间通过事件总线传递的CreateOrderEvent现在已经“消失”或未被库存服务看到,因为在我们过度简化的系统中,没有其他系统对这些事件感兴趣。我的问题是:库存服务(以及整个系统)如何恢复状态,以确保不会错过/未处理任何订单?