你对字符串和字符串字面值的区别产生了困惑。
字符串字面值是指你放在 " 或者 ' 之间的内容,Python 解释器会解析这个字符串并将其存储到内存中。如果你将字符串字面值标记为原始字符串字面值(使用 r'),那么 Python 解释器在将其存储到内存之前不会更改该字符串的表示方式,但是一旦它们被解析,它们在内存中存储的方式完全相同。
这意味着,在内存中不存在所谓的原始字符串。以下两个字符串在内存中以相同的方式存储,没有任何关于它们是否为原始字符串的概念。
r'a regex digit: \d'
'a regex digit: \\d'
这两个字符串都包含\d,没有任何迹象表明这是从原始字符串中提取的内容。所以当你将此字符串传递给re模块时,它会看到有一个\d,并将其视为数字,因为re模块不知道这个字符串来自原始字符串。
在您的特定示例中,要获取一个字面上的反斜杠后跟一个字面上的小写字母"d",您应该使用\\d:
import re
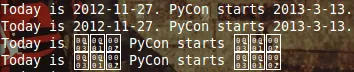
text2 = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text2_re = re.sub(r'(\\d+)/(\\d+)/(\\d+)', r'\3-\1-\2', text2)
print (text2_re)
另一种方法是不使用原始字符串:
import re
text = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text_re = re.sub('(\\d+)/(\\d+)/(\\d+)', '\\3-\\1-\\2', text2)
print (text_re)
text2 = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
text2_re = re.sub('(\\\\d+)/(\\\\d+)/(\\\\d+)', '\\3-\\1-\\2', text2)
print (text2_re)
希望这有所帮助。
编辑: 我不想把事情搞得太复杂,但是因为\d不是一个有效的转义序列,所以Python不会改变它,因此'\d' == r'\d'是真的。由于\\是一个有效的转义序列,它被改变为\,因此你得到了行为'\d' == '\\d' == r'\d'。有时字符串会让人感到困惑。
编辑2: 为了回答你的编辑,让我们具体看每一行:
text2_re = re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
re.sub 接收两个字符串 (\d+)/(\d+)/(\d+) 和 \3-\1-\2。希望现在它的行为符合您的预期。
text2_re1 = re.sub('(\d+)/(\d+)/(\d+)', r'\3-\1-\2', text2)
因为\d不是有效的字符串转义字符,所以它不会被更改(请参见我的第一个编辑),因此re.sub接收两个字符串:(\d+)/(\d+)/(\d+)和\3-\1-\2。由于\d不会被Python解释器更改,r '(\d+)/(\d+)/(\d+)'等同于'(\d+)/(\d+)/(\d+)'。如果您理解我的第一个编辑,那么希望您能够理解这两种情况的行为方式。
text2_re2 = re.sub(r'(\d+)/(\d+)/(\d+)', '\3-\1-\2', text2)
这种情况有些不同,因为\1、\2和\3都是有效的转义序列,它们被替换为其十进制表示给出的Unicode字符。虽然这很复杂,但事实上简单来说就是:
\1 # stands for the ascii start-of-heading character
\2 # stands for the ascii start-of-text character
\3 # stands for the ascii end-of-text character
这意味着re.sub接收第一个字符串,就像前两个示例中一样((\d+)/(\d+)/(\d+)),但第二个字符串实际上是<start-of-heading>/<start-of-text>/<end-of-text>。因此,re.sub精确地用第二个字符串替换匹配,但由于三个值(\1、\2或\3)都不是可打印字符,Python只能打印出一个固定的占位符。
text2_re3 = re.sub('(\d+)/(\d+)/(\d+)', '\3-\1-\2', text2)
这个示例的行为与第三个示例相似,因为r'(\d+)/(\d+)/(\d+)' == '(\d+)/(\d+)/(\d+)',正如第二个示例所解释的那样。