在MySQL中,我想复制一个具有自增列“ID=1”的行,并将数据作为新行插入到同一表中,其中“column ID=2”。如何在单个查询中完成此操作?
16个回答
480
使用 INSERT ... SELECT 语句:
insert into your_table (c1, c2, ...)
select c1, c2, ...
from your_table
where id = 1
其中c1,c2,...是除id之外的所有列。如果您想显式插入一个id为2的记录,则需要在INSERT列列表和SELECT语句中包含它:
insert into your_table (id, c1, c2, ...)
select 2, c1, c2, ...
from your_table
where id = 1
当然,在第二种情况下,您需要注意可能的重复id为2。
- mu is too short
11
1你可以使用 INFORMATION_SCHEMA 编程获取列的名称...我想知道是否可以将其作为子查询和一些字符串函数来完成?嗯... - Yzmir Ramirez
1@Yzmir:最终你会不得不使用动态SQL,这通常需要构建一个存储过程。似乎比起手头有列名列表时更麻烦,不值得这么做。 - mu is too short
10同意。根据我的经验,一旦你开始使用存储过程,就很难回头了——你现在已经和那个数据库结婚了,想改变就需要增加成本。 - Yzmir Ramirez
14@YzmirRamirez,你让婚姻本质上成为了一件坏事。 :) - Prof. Falken
1如何在将所有其他复制字段的列中添加一个自定义值? - Manish Kumar
显示剩余6条评论
63
在我看来,最好的方法似乎是仅使用SQL语句复制该行,同时仅引用您必须和想要更改的列。
CREATE TEMPORARY TABLE temp_table ENGINE=MEMORY
SELECT * FROM your_table WHERE id=1;
UPDATE temp_table SET id=0; /* Update other values at will. */
INSERT INTO your_table SELECT * FROM temp_table;
DROP TABLE temp_table;
优点:
- 在克隆过程中,SQL语句仅提及需要更改的字段。它们不知道也不关心其他字段。其他字段仅作为附带项,不变。这使得SQL语句更容易编写、阅读、维护和扩展。
- 只使用普通的MySQL语句,无需其他工具或编程语言。
- 一个完全正确的记录会以一次原子操作插入到
your_table中。
- parvus
7
3看起来这个不错的技巧(我喜欢它,但对我无效)在包含TEXT/VARCHAR列的表格上不起作用。我尝试了一下,结果出现了:(1163):所使用的表类型不支持BLOB/TEXT列。当然,这严重限制了MySQL的使用范围!也许将来这些限制会被解除或在其他数据库系统上它能够发挥作用,但目前它真的太受限制了。 - Juergen
1看起来不错,但是当我在MySQL中运行第一个查询时,出现了“错误代码:1113。表必须至少有1列”的错误。 - physicalattraction
3很多列的最佳答案。
但是,
SET id=NULL 可能会导致错误 Column 'id' cannot be null。
应该替换为
UPDATE temp_table SET id = (SELECT MAX(id) + 1 as id FROM your_table); - Modder1@physicalattraction 你需要确保前两行是一个语句。 - Samuurai
1我喜欢这个,但在 MySql 5.5 上 Null 对我抛出了一个错误。根据 ToolmakerSteve 的说法,0 可以工作。从另一个答案得知:当 MySQL 看到自动递增列的 null(或 0)时,它会自动替换为下一个有效值。不确定为什么 5.5 会抛出错误。 - user1544428
显示剩余2条评论
17
假设表名为 user(id, user_name, user_email)。
你可以使用以下查询语句:
INSERT INTO user (SELECT NULL,user_name, user_email FROM user WHERE id = 1)
- Vijay
4
40在使用INSERT语句时,始终要指定列名,否则当架构发生变化时,会出现奇怪且意外的错误。 - mu is too short
5确实奇怪而有趣。 :D - sparkyShorts
1不支持SQLite。
结果:附近有“SELECT”:语法错误 - kyb在PostgreSQL中出现错误:
ERROR: 列"id"中的空值。 - Arqam Rafay15
这很有用,它支持BLOB/TEXT列。
CREATE TEMPORARY TABLE temp_table
AS
SELECT * FROM source_table WHERE id=2;
UPDATE temp_table SET id=NULL WHERE id=2;
INSERT INTO source_table SELECT * FROM temp_table;
DROP TEMPORARY TABLE temp_table;
USE source_table;
- Petr Hladík
7
2这种方法比其他答案更好在哪里? - Smar
5如果你有一个包含100个字段的表格,我认为它很不错。除了可能会在ID上设置非空约束条件而导致失败。 - Loïc Faure-Lacroix
错误代码:1136。列计数与第1行的值计数不匹配。 - Oleksii Kyslytsyn
1这不是几年前Parvus说的吗? - ToolmakerSteve
1@ToolmakerSteve,另一个显然不支持“BLOB/TEXT列”。 - ChiefTwoPencils
显示剩余2条评论
9
如果你需要一个快速、干净的解决方案,并且不需要给列命名,你可以使用这里描述的预编译语句: https://dev59.com/GW855IYBdhLWcg3w_5qm#23964285
如果你需要一个复杂的解决方案,以便经常使用此功能,则可以使用以下过程:
DELIMITER $$
CREATE PROCEDURE `duplicateRows`(_schemaName text, _tableName text, _whereClause text, _omitColumns text)
SQL SECURITY INVOKER
BEGIN
SELECT IF(TRIM(_omitColumns) <> '', CONCAT('id', ',', TRIM(_omitColumns)), 'id') INTO @omitColumns;
SELECT GROUP_CONCAT(COLUMN_NAME) FROM information_schema.columns
WHERE table_schema = _schemaName AND table_name = _tableName AND FIND_IN_SET(COLUMN_NAME,@omitColumns) = 0 ORDER BY ORDINAL_POSITION INTO @columns;
SET @sql = CONCAT('INSERT INTO ', _tableName, '(', @columns, ')',
'SELECT ', @columns,
' FROM ', _schemaName, '.', _tableName, ' ', _whereClause);
PREPARE stmt1 FROM @sql;
EXECUTE stmt1;
END
你可以通过以下方式运行它:
CALL duplicateRows('database', 'table', 'WHERE condition = optional', 'omit_columns_optional');
示例
duplicateRows('acl', 'users', 'WHERE id = 200'); -- will duplicate the row for the user with id 200
duplicateRows('acl', 'users', 'WHERE id = 200', 'created_ts'); -- same as above but will not copy the created_ts column value
duplicateRows('acl', 'users', 'WHERE id = 200', 'created_ts,updated_ts'); -- same as above but also omits the updated_ts column
duplicateRows('acl', 'users'); -- will duplicate all records in the table
免责声明:此解决方案仅适用于需要经常在多个表中重复复制行的用户。在不良用户手中可能会带来风险。
- curmil
7
如果您能使用MySQL Workbench,可以通过右键单击行并选择“复制行”,然后右键单击空行并选择“粘贴行”,接着更改ID,最后点击“应用”来完成此操作。
复制该行:
复制该行:
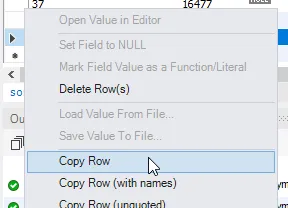
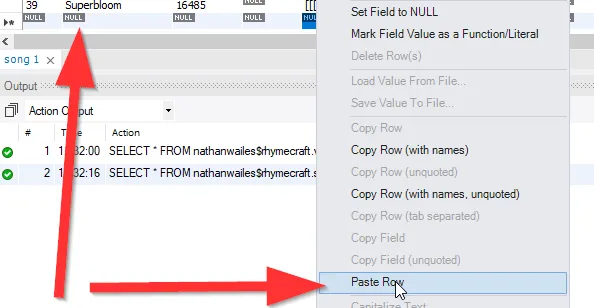
- Nathan Wailes
5
insert into MyTable(field1, field2, id_backup)
select field1, field2, uniqueId from MyTable where uniqueId = @Id;
- IR.Programmer
3
3这个回答相较于其他回答有何优劣之处? - Smar
2@smar 我认为这样更加清晰易懂。 - Satbir Kira
1它保证值被插入到它们各自的列中。 - Vitalis
4
以下是我为正在开发的 Web 应用编写的存储过程示例,用于完成此任务:
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON
-- Create Temporary Table
SELECT * INTO #tempTable FROM <YourTable> WHERE Id = Id
--To trigger the auto increment
UPDATE #tempTable SET Id = NULL
--Update new data row in #tempTable here!
--Insert duplicate row with modified data back into your table
INSERT INTO <YourTable> SELECT * FROM #tempTable
-- Drop Temporary Table
DROP TABLE #tempTable
- RBILLC
1
在当前版本的MariaDB/MySQL中,将id设置为null会出现#1048 - 列'id'不能为空的错误,而将id设置为0则可以正常工作; - shelbypereira
3
您可以将“0”作为列的值传递以自动增量,当记录创建时将使用正确的值。这比临时表简单得多。
来源: 在MySQL中复制行 (请参见第一个解决方案的第二个评论TRiG,由Lore提供)
来源: 在MySQL中复制行 (请参见第一个解决方案的第二个评论TRiG,由Lore提供)
- Mark Pruce
1
1当不接受NULL时,此方法适用于较新版本的MySQL。 - err
1
将数据插入到`dbMyDataBase`.`tblMyTable`表中,包括四个列:`IdAutoincrement`、`Column2`、`Column3`和`Column4`。其中,`IdAutoincrement`列是自增的,`Column2`和`Column3`列的值与源表中相同,`Column4`列的值为"CustomValue"。从`dbMyDataBase`.`tblMyTable`表中选择符合条件"`tblMyTable`.`Column2` = 'UniqueValueOfTheKey'"的行进行插入。这段代码适用于mySQL 5.6版本。
- Wojciech Skibiński
2
3好的,我会尽力进行翻译并保持原意不变。需要翻译的内容是:“Try adding some more detailed explanation, or how this expands on the other answers”。请尝试添加更详细的解释,或说明这如何扩展其他答案。 - Azsgy
这实际上是正确的答案。是的,它很简洁,但任何了解SQL的人都应该“明白”它。我甚至在语句中使用了REPLACE。 - Chiwda
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接