我有一个由256位值组成的数组。 数组很大(数百万条记录),但很少修改,可以放入内存。对于给定的256位数字,我想找到是否存在一个具有至少N位相等的记录。例如,10000和01111没有任何一位相等,1000和1001有3位相等。始终满足N>128,或者更准确地说是N>140。 我不需要找到特定号码,我只需要找出列表中是否存在这样的号码。
是否有一种数据结构或某种索引类型可以加速搜索?
是否有一种数据结构或某种索引类型可以加速搜索?
我可能错了,但是看起来您可以将数据索引为按位 trie,对于您的情况,它在结构上与二叉树相同,但解释方式不同。这里有一个插图(source):
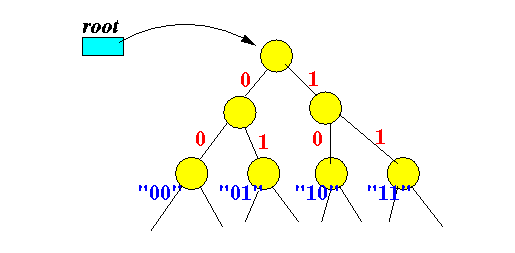
为了简单起见,让我们将您的256位数字视为具有256个数字(当然也是二进制)的向量。有了上面这样的树,您可以通过沿着树向下走并测试后续分支(“0”或“1”)是否存在来在256步或更少的步骤中找到特定向量是否存在于数据集中。类似这样(代码相当原始,但您应该能够理解):
def exists(node, v, i):
"""Checks if subvector of v starting from index i exists in
sub-tree defined by node
"""
if i == len(v):
return True
elif v[i] == 0 and node.left:
return exists(node.left, v, i + 1)
elif v[i] == 1 and node.right:
return exists(node.right, v, i + 1)
else:
return False
v决定向左或向右分支前进。但您还需要处理最多K个不同的元素。好的,为什么不使用错误计数并同时处理两个分支呢?def exists(node, v, i, err_left=K):
"""Checks if subvector of v starting from index i exists in
sub-tree defined by node with up to err_left errors.
"""
if i == len(v):
return True
elif v[i] == 0:
if node.left:
return exists(node.left, v, i + 1, err_count)
elif node.right:
return exists(node.left, v, i + 1, err_left - 1) # proceed, but decrease
# errors left
else:
return False
elif v[i] == 1:
if node.right:
return exists(node.right, v, i + 1, err_count)
elif node.left:
return exists(node.right, v, i + 1, err_left - 1) # proceed, but decrease
# errors left
else:
return False
else:
return False
int compare(long l1, long l2)
{
//Use xor to get what bits are the same
long xor = ~ (l1 ^ l2);
//count the number of bits with value = 1
int count = 0;
while(xor != 0)
{
//check if the right bit is 1, using & operator beetween our number and 0000001
if(xor & 1 > 0) count++;
//shift right the bits
xor = xor >> 1
}
return count;
}
count >= N时退出while循环。1的位数的方法。n次才能找到最大项,其中n是数组的长度。 - concaO(n)的时间,但可以降低每个查询的复杂度。我会再次研究这个问题,它非常有趣,谢谢! - conca