我是一位新手,对声音处理非常陌生,所以我的问题可能很简单。 我想做的是使用 R 从 WAV 文件中提取特定的频率范围(比如 150-400 Hz)。换句话说,我想创建另一个仅包含我指定频率组件(150 到 400 Hz 或其他)的 wave 文件(wave2)。
我在网上看到了一些资料,发现可以通过 FFT 分析来实现这个目的,��问题随之而来。
假设我有以下代码:
library(sound)
s1 <- Sine(440, 1)
s2 <- Sine(880, 1)
s3 <- s1 + s2
s3.s <- as.vector(s3$sound)
# s3.s is now a vector, with length 44100;
# bitrate is 44100 (by default)
# so total time of s3 is 1sec.
# now I calculate frequencies
N <- length(s3.s) # 44100
k <- c(0:(N-1))
Fs <- 44100 # sampling rate
T <- N / Fs
freq <- k / T
x <- fft(s3.s) / N
plot(freq[1:22050], x[1:22050], type="l") # we need just the first half of FFT computation
我们得到的图形如下:
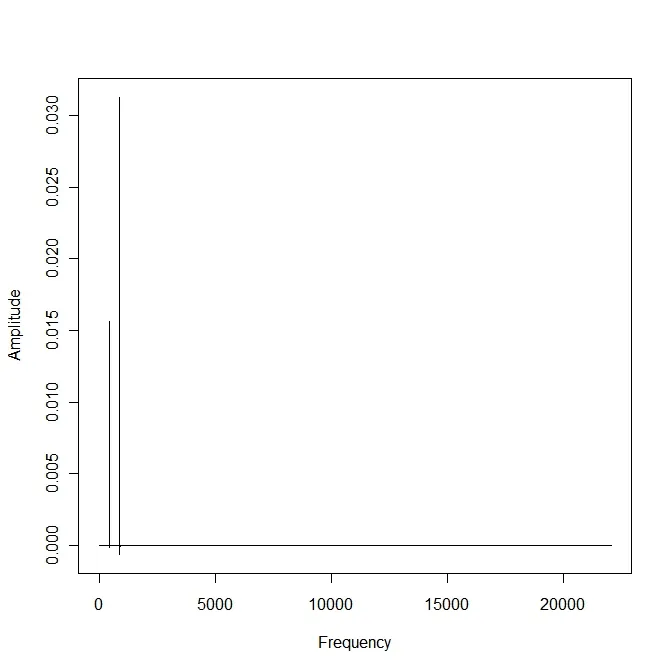
order(Mod(x)[1:22050], decreasing=T)[1:10]
[1] 441 881 882 880 883 442 440 879 884 878
前两个值与我用来创建声音的频率非常接近:
real computed
Freq1: 440 | 441
Freq2: 880 | 881
所以,现在问题来了:如果我想从声音中删除频率范围内的频率,比如说
(1, 500)怎么办?如何选择(并保存)只有范围(1, 500)的部分?
我的期望是,我的新声音(删除了频率)会接近于简单的Sine(freq=880, duration=1)(我知道,它不可能完全像这样!)。
这种可能吗?我相当确定
fft(DATA, inverse = TRUE)是我需要的。但我不确定,并且不知道该如何继续。
play(s1)play(s2)和play(s3)。正是频率的混合导致了“不好听”的声音。也许你可以选择一个范围内的中间/中位数频率,而不是提取一系列频率。 - bill_080(junk1 <- median(junk[junk > 500]))来完成。 - bill_080play()函数时,我发现了一些奇怪的结果。长话短说,尝试使用play(s3)和play(s3/2)。s3由两个频率组成。如果你建立了Z个频率,请将其除以Z来播放。 - bill_080(-1,1)范围内。这可以通过库sound的normalize函数来完成。在FFT分析后,我尝试重建原始声音。绘制plot(normalize(s3[1:600]))和plot(normalize(junk4[1:600]+junk2[1:600]))(junk2包含频率> 500,junk4频率< 500),将向您展示一个相当不错的结果(尽管我必须找到更好的近似值)。谢谢你的帮助,贝尔! - Tommaso