我正在学习Transformer。这里是PyTorch文档中MultiheadAttention的介绍。在它们的实现中,我发现有一个限制:
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
为什么要求约束条件:embed_dim必须被num_heads整除?如果我们回到这个方程:

假设:
Q,K,V 是 n x emded_dim 的矩阵;所有的权重矩阵 W 是 emded_dim x head_dim 的。
那么,拼接 [head_i, ..., head_h] 将会是一个 n x (num_heads*head_dim) 的矩阵;
W^O 的大小为 (num_heads*head_dim) x embed_dim。
[head_i, ..., head_h] * W^O 将变成一个 n x embed_dim 的输出。
我不知道为什么我们需要 embed_dim必须被num_heads整除。
假设我们有 num_heads=10000,结果是相同的,因为矩阵乘法将吸收这个信息。
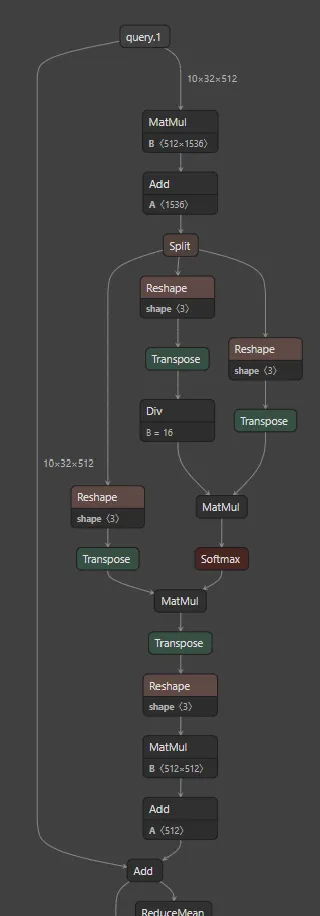
seq_len x emb_dim是20 x 9,且num_heads=2,选择head_dim=77作为例子,那么我们可以得到head_i是一个20 x 144的矩阵。因此,[head_1, head_2]是20 x 288,我们仍然可以选择W^O为288 x 9。最终我们可以得到20 x 9的结果。我的观点是,我们也可以将emb_dim映射到任何长度,并使用W^O将其投影回emb_dim。为什么需要将emb_dim分成偶数长度?谢谢。 - jason