有没有一种简单的方式可以使用列表推导来展开可迭代对象的列表,或者如果无法做到这一点,你们认为最好的展开浅层次列表的方法是什么,需要在性能和可读性之间取得平衡?
我尝试使用嵌套的列表推导来展开这样的列表,像这样:
[image for image in menuitem for menuitem in list_of_menuitems]
但是在那里我遇到了NameError错误,因为name 'menuitem' is not defined。在谷歌搜索和Stack Overflow上查看后,我使用了一个reduce语句来得到所需的结果:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
但是这种方法相当难以阅读,因为我需要在那里调用list(x),因为x是Django QuerySet对象。
结论:
感谢所有为这个问题做出贡献的人。以下是我所学到的内容总结。我还将此作为社区维基,以便其他人可以添加或更正这些观察结果。
我的原始reduce语句是多余的,最好改成这样:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
这是嵌套列表推导式的正确语法(dF总结得非常好!):
>>> [image for mi in list_of_menuitems for image in mi]
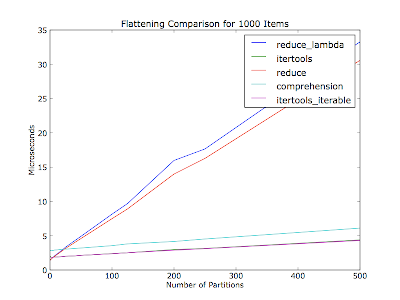
但是,这两种方法都不如使用 itertools.chain 高效:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
正如@cdleary所指出的,使用chain.from_iterable 可能更好地避免了*操作符的魔法:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]