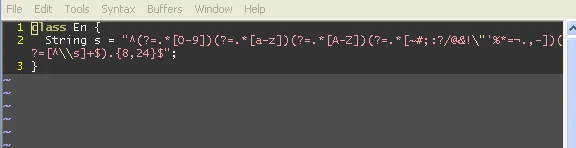
我在下面的方法中遇到了编译错误。
public static boolean isValidPasswd(String passwd) {
String reg = "^(?=.*[0-9])(?=.*[a-z])(?=.*[A-Z])(?=.*[~#;:?/@&!\"'%*=¬.,-])(?=[^\\s]+$).{8,24}$";
return Pattern.matches(reg, passwd);
}
在 Utility.java 文件中,[76,74] 处存在一个无法映射的字符,该字符为双引号 (" )。
如何解决这个问题?谢谢。