我正在使用Sigmoid激活函数和二元交叉熵训练二元分类器,可以获得约98%的良好准确性。但是,当我使用softmax和分类交叉熵进行训练时,准确率很低(<40%)。我将二元交叉熵的目标传递为0和1的列表,例如[0,1,1,1,0]。
有任何想法,为什么会出现这种情况?
这是我用于第二个分类器的模型: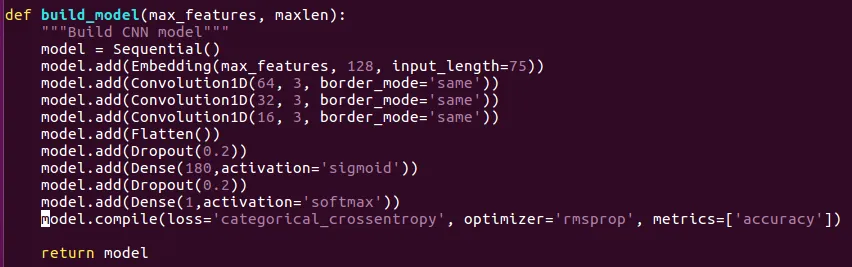
有任何想法,为什么会出现这种情况?
这是我用于第二个分类器的模型:
现在,您的第二个模型总是回答“Class 0”,因为它只能在最后一层中选择一个类(输出数量)。
由于您有两个类别,因此需要在两个输出上计算softmax + categorical_crossentropy以选择最可能的类别。
因此,您的最后一层应该是:
model.add(Dense(2, activation='softmax')
model.compile(...)
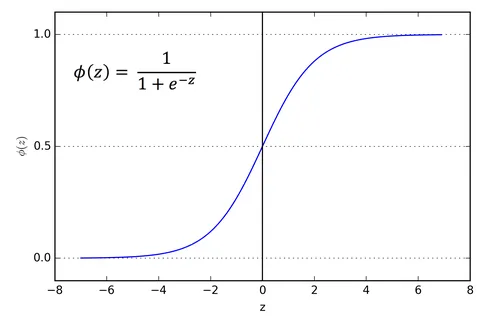
Sigmoid(-infinity) = 0
Sigmoid(0) = 0.5
Sigmoid(+infinity) = 1