我最近意识到,尽管我在生活中经常使用二叉搜索树(BST),但我从未考虑过除中序遍历以外的其他遍历方式(虽然我知道如何轻松地调整程序以使用前序或后序遍历)。
在意识到这一点后,我拿出了一些旧的数据结构教科书,寻找前序遍历和后序遍历有用性背后的原因-不过他们没有说太多。
有哪些实际场景下需要使用先序/后序遍历呢?什么情况更适合使用先序/后序而不是中序遍历?
我最近意识到,尽管我在生活中经常使用二叉搜索树(BST),但我从未考虑过除中序遍历以外的其他遍历方式(虽然我知道如何轻松地调整程序以使用前序或后序遍历)。
在意识到这一点后,我拿出了一些旧的数据结构教科书,寻找前序遍历和后序遍历有用性背后的原因-不过他们没有说太多。
有哪些实际场景下需要使用先序/后序遍历呢?什么情况更适合使用先序/后序而不是中序遍历?
在了解何时使用二叉树的先序、中序和后序遍历之前,您必须了解每种遍历策略的工作原理。以下以该树为例:
树的根节点为7,最左边的节点是0,最右边的节点是10。
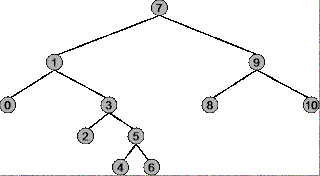
先序遍历:
概述:从根节点(7)开始,以最右侧节点(10)结束。
遍历顺序:7、1、0、3、2、5、4、6、9、8、10
中序遍历:
概述:从最左边的节点(0)开始,以最右边的节点(10)结束。
遍历顺序:0、1、2、3、4、5、6、7、8、9、10
后序遍历:
概述:从最左边的节点(0)开始,以根节点(7)结束。
遍历顺序:0、2、4、6、5、3、1、8、10、9、7
程序员选择的遍历策略取决于正在设计的算法的特定需求。目标是速度,因此选择可以最快获取所需节点的策略。
如果您知道需要在检查任何叶子之前探索根节点,则选择先序遍历,因为您将在所有叶子之前遇到所有根。
如果您知道需要在任何节点之前探索所有叶子,则选择后序遍历,因为您不会浪费时间检查寻找叶子的根。
如果您知道树中存在节点的内在顺序,并且希望将树展平回其原始顺序,则应使用中序遍历。树将以创建它的相同方式被展平。 先序或后序遍历可能无法将树解开回创建它的序列。
struct Node{
int data;
Node *left, *right;
};
void preOrderPrint(Node *root)
{
print(root->name); //record root
if (root->left != NULL) preOrderPrint(root->left); //traverse left if exists
if (root->right != NULL) preOrderPrint(root->right);//traverse right if exists
}
void inOrderPrint(Node *root)
{
if (root.left != NULL) inOrderPrint(root->left); //traverse left if exists
print(root->name); //record root
if (root.right != NULL) inOrderPrint(root->right); //traverse right if exists
}
void postOrderPrint(Node *root)
{
if (root->left != NULL) postOrderPrint(root->left); //traverse left if exists
if (root->right != NULL) postOrderPrint(root->right);//traverse right if exists
print(root->name); //record root
}
预序遍历:用于创建树的副本。例如,如果您想要创建一棵树的复制品,请使用预序遍历将节点放入数组中。然后对数组中的每个值执行插入操作,以在新树上执行此操作。最终将得到原始树的副本。
中序遍历:用于按非递减顺序获取BST中节点的值。
后序遍历:用于从叶子到根删除树。
- ROOT
- A
- B
- C
- D
- E
- F
- G
先序遍历和后序遍历分别与自顶向下和自底向上的递归算法相关。如果您想以迭代方式编写给定的二叉树递归算法,则基本上就是这样做。
此外,请注意,先序遍历和后序遍历序列一起完全指定了手头的树,从而产生了紧凑的编码(对于稀疏树至少如此)。
有很多情况下,这种差异会发挥真正的作用。
我要指出一个很好的例子,那就是编译器的代码生成。考虑以下语句:
x := y + 32
class Solution:
def kthSmallest(self, root: Optional[TreeNode], k: int) -> int:
res=None
def inorder(node):
if not node:
return
# in bst this is the smallest value
inorder(node.left)
# python determines the scope at creation time of the function
nonlocal k
k-=1
if k==0:
nonlocal res
res=node.val
return
inorder(node.right)
inorder(root)
return res
class Solution:
def isBalanced(self, root: Optional[TreeNode]) -> bool:
def post_order(root):
# leaf node is balanced
if not root:
# we carry the height of each subtree
return [True,0]
# with recursion, we start from bottom, so we do not have repetitive work
left,right=post_order(root.left),post_order(root.right)
# if any of the subtree return false, then we know entire tree is not balanced
balanced=left[0] and right[0] and abs(left[1]-right[1])<=1
# 1+max(left[1],right[1]) is the height of the each subtree. 1 is the root of the subtree
return [balanced,1+max(left[1],right[1])]
return post_order(root)[0]
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:
if not preorder or not inorder:
return None
# first element of preorder is root
root=TreeNode(preorder[0])
# mid value in inorder gives us root. left values of root will be the left subtree, right values will be the right subtree
# mid tells us how many elements we want from left subtree and howmany for right subtree
mid = inorder.index(preorder[0])
# we took 1 out of each array. preorder will not include the first, inorder will not include the mid value
root.left=self.buildTree(preorder[1:mid+1],inorder[:mid])
root.right=self.buildTree(preorder[mid+1:],inorder[mid+1:])
return root
顺序:为了从任何解析树中获取原始输入字符串,因为解析树遵循运算符的优先级。首先遍历最深的子树。因此,父节点中的运算符优先级低于子树中的运算符。