我刚开始使用GHC 6.12进行Haskell半显式并行编程。我编写了以下Haskell代码,对列表中的4个元素计算斐波那契函数的映射,并同时对两个元素计算sumEuler函数的映射。
import Control.Parallel
import Control.Parallel.Strategies
fib :: Int -> Int
fib 0 = 0
fib 1 = 1
fib n = fib (n-1) + fib (n-2)
mkList :: Int -> [Int]
mkList n = [1..n-1]
relprime :: Int -> Int -> Bool
relprime x y = gcd x y == 1
euler :: Int -> Int
euler n = length (filter (relprime n) (mkList n))
sumEuler :: Int -> Int
sumEuler = sum . (map euler) . mkList
-- parallel initiation of list walk
mapFib :: [Int]
mapFib = map fib [37, 38, 39, 40]
mapEuler :: [Int]
mapEuler = map sumEuler [7600, 7600]
parMapFibEuler :: Int
parMapFibEuler = (forceList mapFib) `par` (forceList mapEuler `pseq` (sum mapFib + sum mapEuler))
-- how to evaluate in whnf form by forcing
forceList :: [a] -> ()
forceList [] = ()
forceList (x:xs) = x `pseq` (forceList xs)
main = do putStrLn (" sum : " ++ show parMapFibEuler)
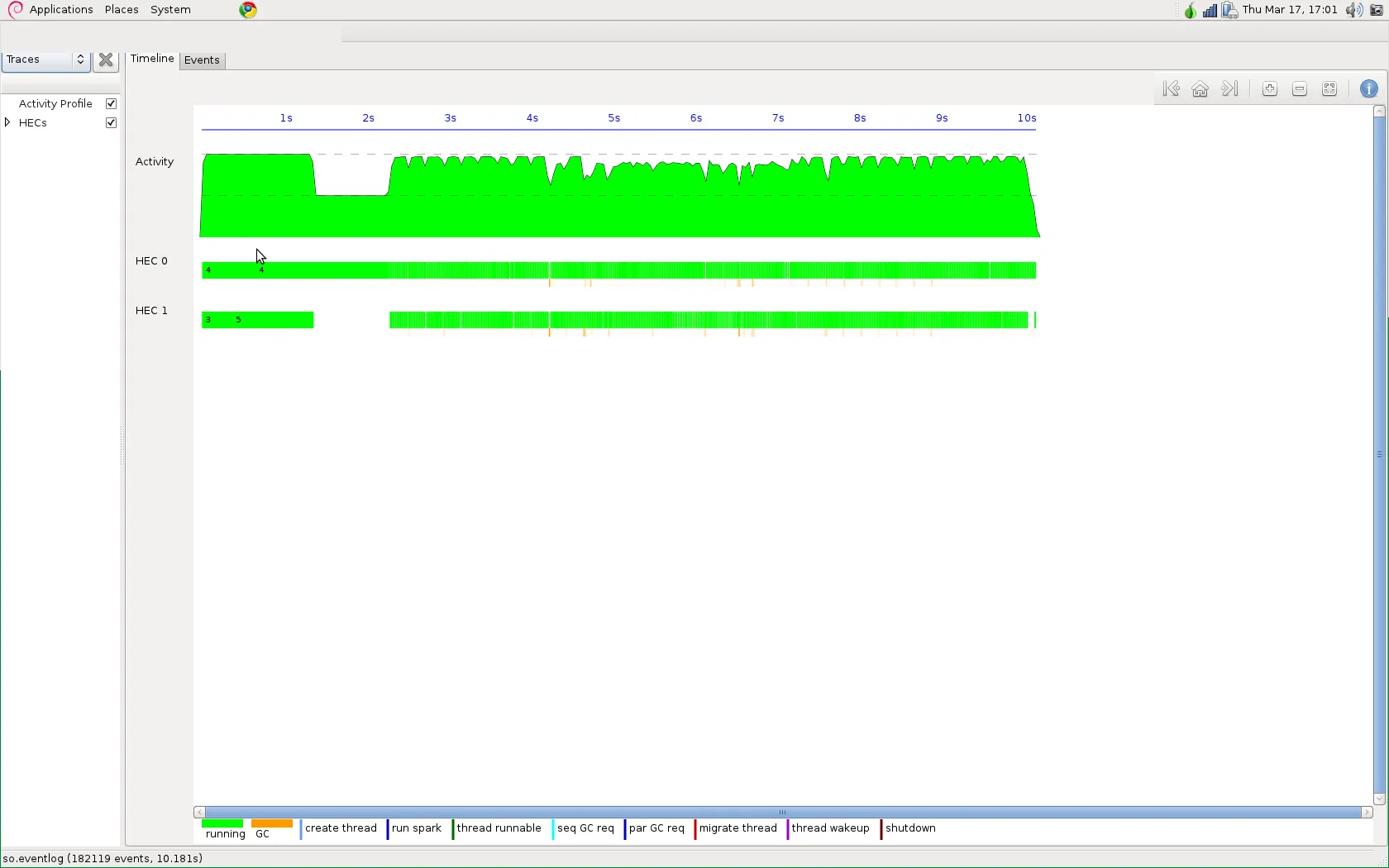
为了提高我的程序的并行性能,我使用了par和pseq以及一个forcing函数来强制进行whnf评估的重写。但问题是,在查看Threadscope时,我发现没有获得任何并行性,并且速度也没有提升。
这就是为什么我有以下两个问题:
问题1:如何修改我的代码以利用任何并行性?
问题2:如何编写我的程序以使用策略(如parMap、parList、rdeepseq等)?
通过策略的第一个改进
根据他的贡献
parMapFibEuler = (mapFib, mapEuler) `using` s `seq` (sum mapFib + sum mapEuler) where
s = parTuple2 (seqList rseq) (seqList rseq)
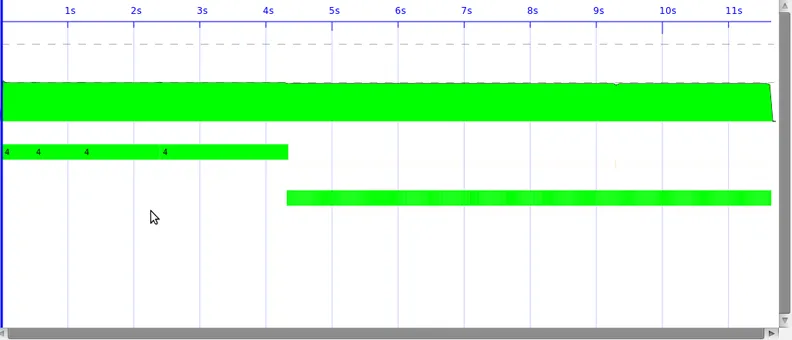
并行性在ThreadScope中出现,但不足以显著提高速度。