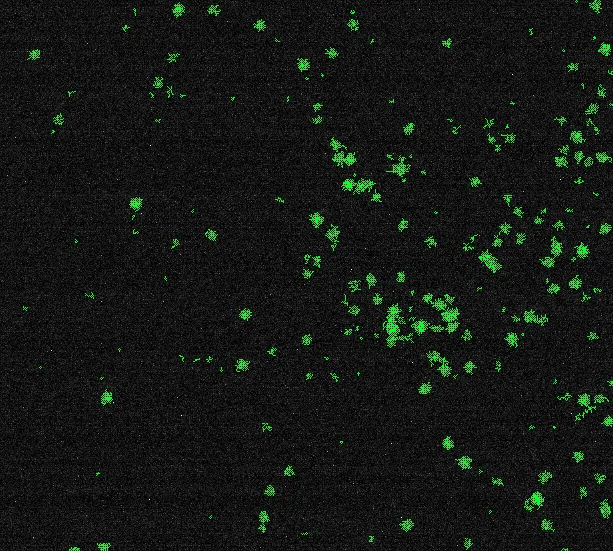
我正在寻找一种适当的解决方案,以便在这张图片中计算粒子数量并测量它们的大小:

最终我需要得到粒子坐标和面积的列表。经过在互联网上的一些搜索后,我意识到有3种粒子检测方法:
- 斑点
- 轮廓
- connectedComponentsWithStats
由于不同项目中使用了不同的方法,因此我进行了混合编写代码。
import pylab
import cv2
import numpy as np
高斯模糊和阈值处理
original_image = cv2.imread(img_path)
img = original_image
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = cv2.GaussianBlur(img, (5, 5), 0)
img = cv2.blur(img, (5, 5))
img = cv2.medianBlur(img, 5)
img = cv2.bilateralFilter(img, 6, 50, 50)
max_value = 255
adaptive_method = cv2.ADAPTIVE_THRESH_GAUSSIAN_C
threshold_type = cv2.THRESH_BINARY
block_size = 11
img_thresholded = cv2.adaptiveThreshold(img, max_value, adaptive_method, threshold_type, block_size, -3)
过滤小物体
min_size = 4
nb_components, output, stats, centroids = cv2.connectedComponentsWithStats(img, connectivity=8)
sizes = stats[1:, -1]
nb_components = nb_components - 1
# for every component in the image, you keep it only if it's above min_size
for i in range(0, nb_components):
if sizes[i] < min_size:
img[output == i + 1] = 0
生成轮廓以填充空洞和测量。
pos_list 和 size_list 是我们正在寻找的内容。contours, hierarchy = cv2.findContours(img, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
pos_list = []
size_list = []
for i in range(len(contours)):
area = cv2.contourArea(contours[i])
size_list.append(area)
(x, y), radius = cv2.minEnclosingCircle(contours[i])
pos_list.append((int(x), int(y)))
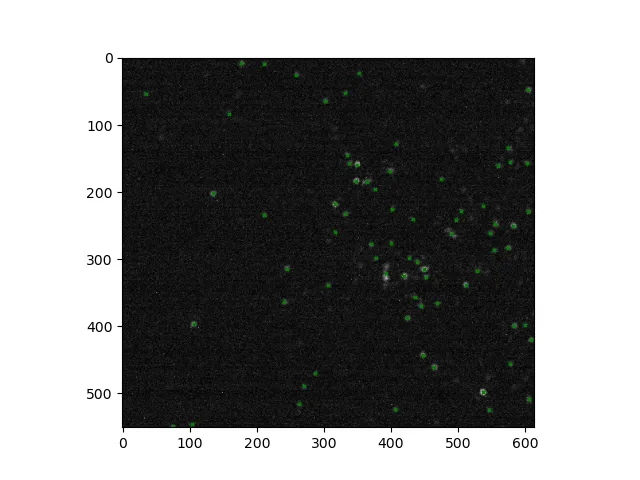
对于自检,如果我们将这些坐标绘制在原始图像上
pts = np.array(pos_list)
pylab.figure(0)
pylab.imshow(original_image)
pylab.scatter(pts[:, 0], pts[:, 1], marker="x", color="green", s=5, linewidths=1)
pylab.show()
我们可能会得到以下内容:
如果有人知道如何改进我的解决方案,请分享。