我正在尝试使用spark.sql()或sqlContext.sql()方法(这里的spark是我们在启动EMR Notebook时可用的SparkSession对象变量)在附加到已安装Hadoop、Spark和Livy的EMR集群的EMR笔记本上,使用公共数据集运行SQL查询。 但是,在运行任何基本SQL查询时,我遇到错误:
AnalysisException: u'java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient;
我想使用SQL查询,因此不希望使用Dataframe API作为替代方案。
这个Spark EMR集群没有安装单独的Hive组件,我也不打算使用它。我已经尝试寻找此问题的各种原因,其中一个可能是EMR笔记本可能没有写入权限来创建metastore_db。但是,我无法确认这一点。我已经试图在集群的日志文件中查找此错误,但未能找到,并且不确定哪个文件可能包含此错误以获取更多详细信息。
重现问题的步骤:
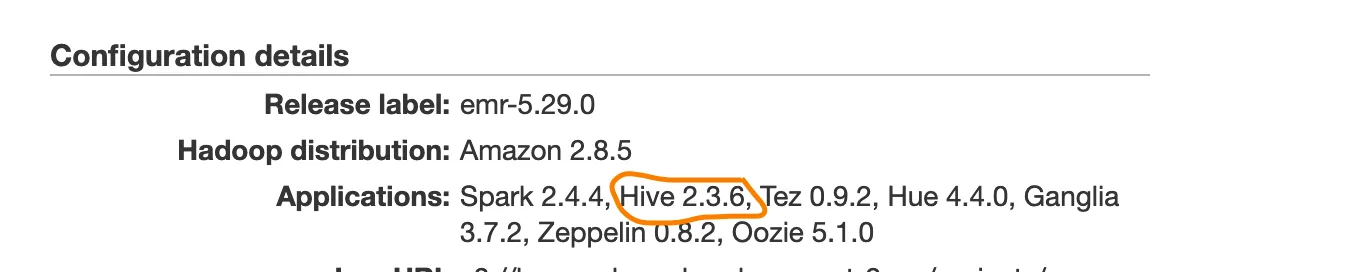
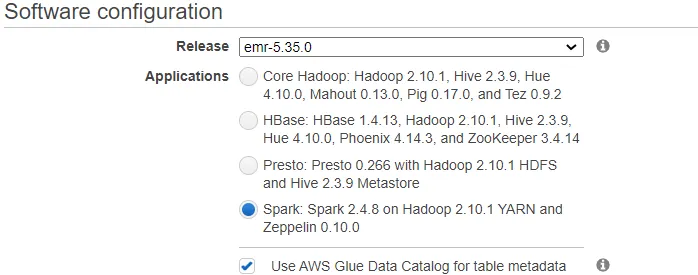
使用控制台创建AWS EMR集群,并使用快速启动视图选择spark选项。它将包括Spark 2.4.3 on Hadoop 2.8.5 YARN with Ganglia 3.7.2和Zeppelin 0.8.1。它可以只有1个主节点和2个核心节点,甚至可以只有1个单独的主节点。
从EMR页面上的“Notebooks”链接创建EMR Notebook,将其附加到刚刚创建的集群并打开它(默认情况下,笔记本右上角所选的内核将为pyspark)。
- 我正在使用的代码对公共的亚马逊评论数据集运行spark.sql查询。
- 代码:
# Importing data from s3
input_bucket = 's3://amazon-reviews-pds'
input_path = '/parquet/product_category=Books/*.parquet'
df = spark.read.parquet(input_bucket + input_path)
# Register temporary view
df.createOrReplaceTempView("reviews")
sqlDF = sqlContext.sql("""SELECT product_id FROM reviews LIMIT 5""")
我期望从这个数据集中返回5个产品ID,但我收到了错误信息:
u'java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient;'
Traceback (most recent call last):
File "/usr/lib/spark/python/lib/pyspark.zip/pyspark/sql/context.py", line 358, in sql
return self.sparkSession.sql(sqlQuery)
File "/usr/lib/spark/python/lib/pyspark.zip/pyspark/sql/session.py", line 767, in sql
return DataFrame(self._jsparkSession.sql(sqlQuery), self._wrapped)
File "/usr/lib/spark/python/lib/py4j-0.10.7-src.zip/py4j/java_gateway.py", line 1257, in __call__
answer, self.gateway_client, self.target_id, self.name)
File "/usr/lib/spark/python/lib/pyspark.zip/pyspark/sql/utils.py", line 69, in deco
raise AnalysisException(s.split(': ', 1)[1], stackTrace)
AnalysisException: u'java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient;'