以下是一些与永久文件/屏幕截图链接的解决方案。
A) 正则表达式 - re2 (Sheets)
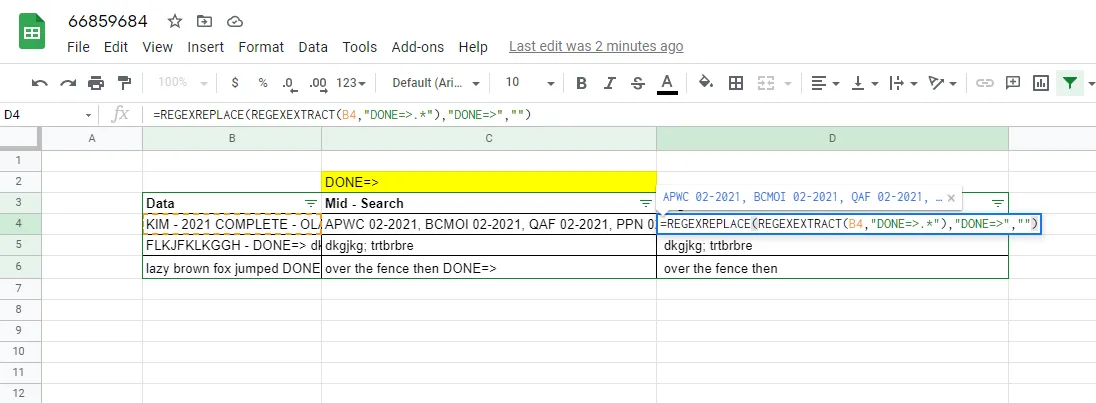
请参见此处的文件关联屏幕截图。
B) Mid / Search 公式
=Mid(B4,search($C$3,B4)+len($C$3)+1,len(B4))
其中:
- 第一个“data”点位于单元格B4(即您提供的句子“KIM-2021COMPLETE-OLAP-03-01-2021 … DONE => APWC ...”)
- 期望的“trigger”单词在单元格C3中(例如“DONE =>”)- 您可以将其更改为任何您希望的内容(仅选择第一次出现,并返回其后的所有内容作为所需结果。)
- 返回的文本:列C(第一个结果在单元格C4中)
它是如何工作的
- Mid(target,a,b)从“目标”单元格开始,从第“ath”个位置的字符开始,返回文本中的b个字符
- 例如,对于target =“Hello”,a = 2和b = 3,Mid(“Hello”,2,3)=“ell”(不使用引号)
- 对于您的情况,使用a = search(“DONE =>”)会从此点(单词起始处)返回文本,因此a = search(“DONE =>”)+ len(“DONE =>”)+1应该将要返回的字符串的第一个字符放置在单词“DONE =>”的第一次出现之后立即
- len(string)只是返回定义为string的变量的长度。例如len(“Hello”)= 5。由于“DONE =>”后面的字符数不能超过原始文本(即您的“数据”)中的总字符数,因此Excel将自动限制为最大可用字符数,因此您可以放心地假定在“DONE =>”之后返回所有字符(假设此单词出现在Data中)
- Iferror和Trim仅是为了确保更清晰的结果(例如缺少“DONE =>”,多余的空格字符等)
屏幕截图
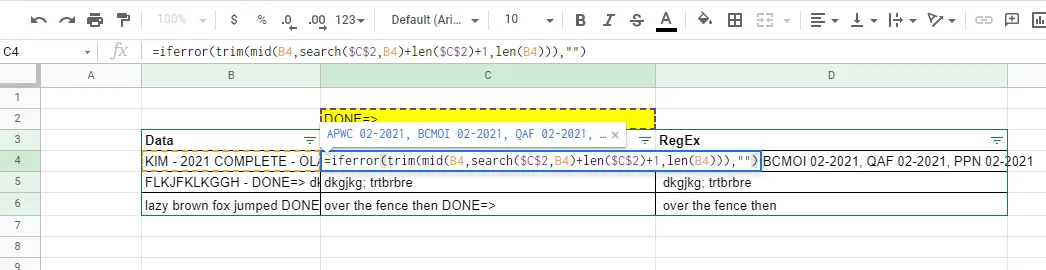
mid/search示例的公式
C)正则表达式变化
Sheets使用re2进行正则表达式。普通的正则表达式看起来像这样:
(DONE=>\K)..+
请参见此处(提供永久链接可转换为Python / Java等)。例如,在Python中,可以按以下方式工作:
import re
regex = r"(DONE=>\K)..+"
test_str = "KIM - 2021 COMPLETE - OLAP - 03-01-2021...DONE=> APWC 02-2021, BCMOI 02-2021, QAF 02-2021, PPN 02-2021"
matches = re.finditer(regex, test_str, re.MULTILINE)
for matchNum, match in enumerate(matches, start=1):
print ("Match {matchNum} was found at {start}-{end}: {match}".format(matchNum = matchNum, start = match.start(), end = match.end(), match = match.group()))
for groupNum in range(0, len(match.groups())):
groupNum = groupNum + 1
print ("Group {groupNum} found at {start}-{end}: {group}".format(groupNum = groupNum, start = match.start(groupNum), end = match.end(groupNum), group = match.group(groupNum)))
D) 相关链接
DONE=>,像这个结果DONE=> APWC 02-2021, BCMOI 02-2021, QAF 02-2021, PPN 02-2021,是否可以实现。 - user15169505"DONE=>\s*.+\b"。 - Wiktor Stribiżew