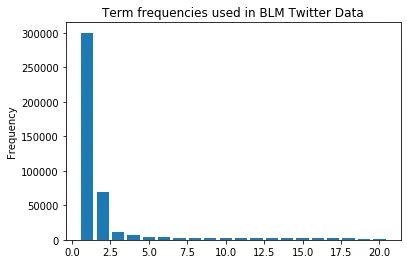
我编写了一个函数,用于输出和绘制文本中出现最频繁的单词。请参见下面的代码和输出。
tf = Counter()
for i in list(tweet['text']):
temp=XXX
for tag, count in tf.most_common(20):
print("{}: {}".format(tag, count))
y = [count for tag, count in tf.most_common(20)]
x = range(1, len(y)+1)
plt.bar(x, y)
plt.title("Term frequencies used inTwitter Data")
plt.ylabel("Frequency")
plt.savefig('us-iran-term-distn.png')
输出结果是带有以下图表的最常见单词:
blacklivesmatter: 127336
blm: 58619
black: 25973
people: 17960
.
.
lives: 11684
police: 10762
matter: 9902
white: 9766
georgefloyd: 9023
protest: 8734
请问如何在 x 轴上添加出现频率最高的单词?
非常感谢!
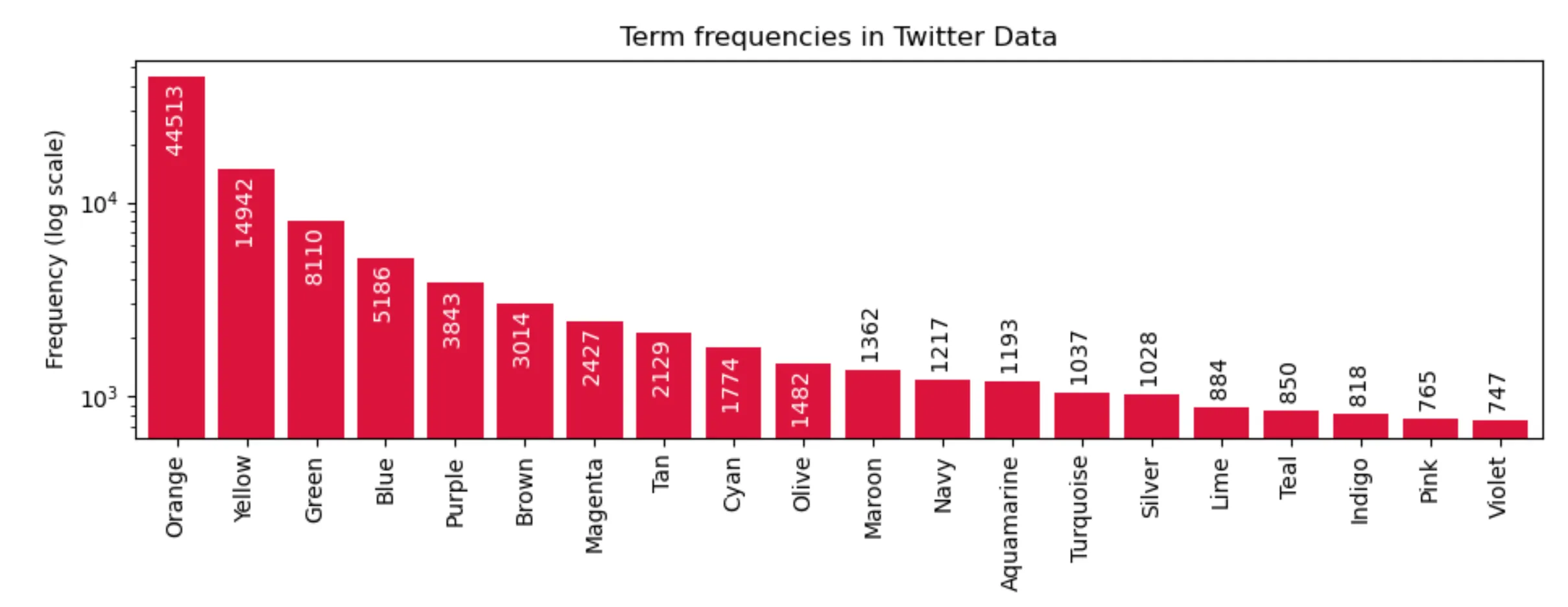
plt.xticks(rotation=90),它会使标签可读。请在您方便时回答问题,以便我可以接受它。谢谢。 - bravopapa