例子: 我有一个数据框,其中第一列是
dat <- c("A","B","C","A")
然后我有另一个数据框,其中第一列的内容是:
dat2[, 1]
[1] A B C
Levels: A B C
dat2[, 2]
[1] 21000 23400 26800
如何将第二个数据框(dat2)的值添加到第一个数据框(dat)中?
在第一个数据框中存在重复项,每当出现“A”时,我希望将第二个数据框对应的值(21000)相加到新列中。
例子: 我有一个数据框,其中第一列是
dat <- c("A","B","C","A")
然后我有另一个数据框,其中第一列的内容是:
dat2[, 1]
[1] A B C
Levels: A B C
dat2[, 2]
[1] 21000 23400 26800
如何将第二个数据框(dat2)的值添加到第一个数据框(dat)中?
在第一个数据框中存在重复项,每当出现“A”时,我希望将第二个数据框对应的值(21000)相加到新列中。
dat1 <- data.frame(x1 = c("A","B","C","A"), stringsAsFactors = FALSE)
dat2 <- data.frame(x1 = c("A","B","C"),
x2 = c(21000, 23400, 26800), stringsAsFactors = FALSE)
match函数。dat1$dat2_vals <- dat2$x2[match(dat1$x1, dat2$x1)]
将字符列转换为character类型而不是factor类型非常重要,否则元素将无法匹配。我提到这一点是因为你的dat2中有一个levels属性。
我比较喜欢的第三种选项是使用dplyr中的left_join...相对于使用merge处理大型数据框来说,这个方法似乎更快。
require(dplyr)
dat1 <- data.frame(x1 = c("A","B","C","A"), stringsAsFactors = FALSE)
dat2 <- data.frame(x1 = c("A","B","C"),
x2 = c(21000, 23400, 26800), stringsAsFactors = FALSE)
dat1 <- left_join(dat1, dat2, by="x1")
让我们用microbenchmark来比赛大型数据帧,只是为了好玩!
创建大型数据帧
dat1 <- data.frame(x1 = rep(c("A","B","C","A"), 1000), stringsAsFactors = FALSE)
dat2 <- data.frame(x1 = rep(c("A","B","C", "D"), 1000),
x2 = runif(1,0), stringsAsFactors = FALSE)
预备,就绪,出发!
library(microbenchmark)
mbm <- microbenchmark(
left_join = left_join(dat1, dat2, by="x1"),
merge = merge(dat1, dat2, by = "x1"),
times = 20
)
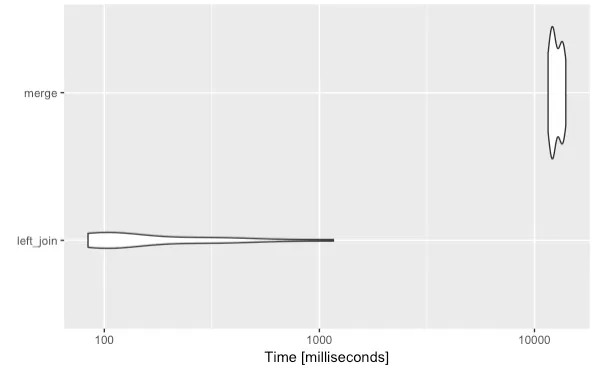
merge 函数。# Input data
dat <- data.frame(ID = c("A", "B", "C", "A"))
dat2 <- data.frame(ID = c("A", "B", "C"),
value = c(1, 2, 3))
# Merge two data.frames by specified column
merge(dat, dat2, by = "ID")
ID value
1 A 1
2 A 1
3 B 2
4 C 3