我打算使用Scala和Akka设计分布式系统。我想从集群中聚合跟踪消息,并有可能在某种UI中查看它们。Zipkin是最好的解决方案吗?还是Flume(+一些包装器)或其他什么东西?
Scala的分布式跟踪解决方案?
4
- Alexander Chepurnoy
3
1你对“最好”的标准是什么? - om-nom-nom
我面临着一个类似的情况,但收集的数据是业务关键的。我们考虑直接将其发送到HBase。 - Randall Schulz
最适合我的 = 易于使用,依赖性少,问题少,文档完善。我只需要监控当前系统状态。 - Alexander Chepurnoy
1个回答
8
Zipkin是最好的解决方案。
--zipkin开发者
编辑 - 好的,我会认真回答:
Zipkin是由Twitter开发的分布式跟踪系统,因为我们的面向服务的架构非常庞大,所以经常很难理解任何给定请求中到底发生了什么。这是真的,以下是在Twitter中所有服务依赖关系的Zipkin可视化:
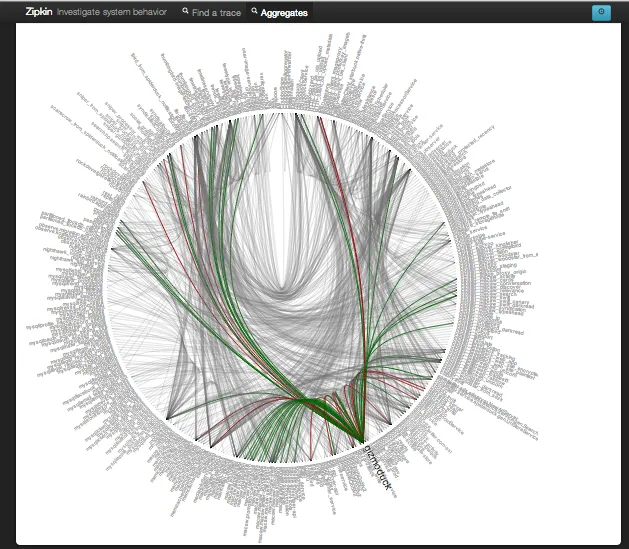
你的平台也这么复杂吗?你应该使用zipkin。我是否提到它是我见过的最好的扩展系统之一?它毫不费力地跟得上Twitter级别的负载,如果您的规模很大,这可能对您很重要。
你说什么?你没有Twitter那么大?你只有三个服务:一个Web前端,某种中间件和数据库后端?也许Zipkin对你来说有点过度kill。我们已经做了一些工作,使它更容易设置,但实际上我的工作不是为您让Zipkin变得容易,而是为了让Zipkin成为Twitter的杰出系统。
不过,如果您计划扩展Scala,Twitter的Finagle等堆栈是非常出色的。不要让Typesafe的所有布道者欺骗您。当您尝试在大规模架构中部署时,他们的堆栈有一些严重的缺陷。但再说一遍,我们的工作不是告诉您我们的堆栈有多好,甚至不是帮助您使用它。我们的工作是使我们的堆栈变得杰出。
- bmdhacks
5
1+1 for being bold :-) - om-nom-nom
-1 不是注释。 - Travis Brown
哎,这个问题太含糊了。 - bmdhacks
哈哈,这张照片太疯狂了。我只会有大约10台机器来运行数据处理任务,想要知道当前系统的状态(失败任务数量,队列溢出等)。这与Twitter的情况相去甚远。 - Alexander Chepurnoy
1@AlexanderChepurnoy,那么通常的度量标准+graphite/ganglia方法应该就可以了。 - om-nom-nom
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接