我有一个类型为((id, ts), some value)的有序RDD。这使用了一个自定义分区器,仅在id字段上进行分区。
math.abs(id.hashCode % numPartitions)
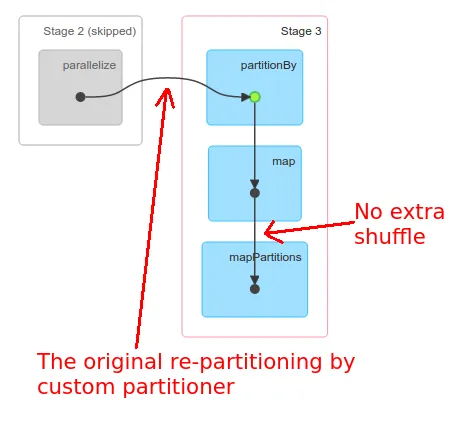
现在,如果我在这个分区的RDD上运行以下两个函数,它会涉及到数据集的洗牌和重新分区吗?
val partitionedRDD: ((id:Long, ts:Long), val:String) = <Some Function>
val flatRDD = orderedRDD.map(_ => (_._1.id, (_._1.ts, _._2)))
我想知道的是,
flatRDD.groupByKey()和flatRDD.reduceByKey()是否会具有与partitionedRDD相同的分区方式,还是Spark会再次洗牌数据集并创建新的分区?谢谢, Devi