我有以下问题:
从0-N的范围内生成M个均匀随机整数,其中N>>M,并且没有一对整数的差小于K。目前我能想到的最好方法是维护一个排序列表,然后确定当前生成整数的下限,并测试它与下一个和上一个元素的关系,如果可以,则将元素插入其中。这是O(nlogn)的复杂度。
是否有更有效的算法?
问题示例:
在0到1亿之间生成1000个均匀随机整数,任意两个整数之间的差值不少于1000。
解决这个问题的全面方法是:
1.确定满足约束条件的所有n-choose-m组合,称之为集合X
2.在[0,|X|)范围内选择一个均匀随机整数i。
3.从X中选择第i个组合作为结果。
当n-choose-m很大时,此解决方案存在问题,因为枚举和存储所有可能的组合将非常昂贵。因此,需要一种高效的在线生成解决方案。
注意:以下是由pentadecagon提供的解决方案的C++实现。
从0-N的范围内生成M个均匀随机整数,其中N>>M,并且没有一对整数的差小于K。目前我能想到的最好方法是维护一个排序列表,然后确定当前生成整数的下限,并测试它与下一个和上一个元素的关系,如果可以,则将元素插入其中。这是O(nlogn)的复杂度。
是否有更有效的算法?
问题示例:
在0到1亿之间生成1000个均匀随机整数,任意两个整数之间的差值不少于1000。
解决这个问题的全面方法是:
1.确定满足约束条件的所有n-choose-m组合,称之为集合X
2.在[0,|X|)范围内选择一个均匀随机整数i。
3.从X中选择第i个组合作为结果。
当n-choose-m很大时,此解决方案存在问题,因为枚举和存储所有可能的组合将非常昂贵。因此,需要一种高效的在线生成解决方案。
注意:以下是由pentadecagon提供的解决方案的C++实现。
std::vector<int> generate_random(const int n, const int m, const int k)
{
if ((n < m) || (m < k))
return std::vector<int>();
std::random_device source;
std::mt19937 generator(source());
std::uniform_int_distribution<> distribution(0, n - (m - 1) * k);
std::vector<int> result_list;
result_list.reserve(m);
for (int i = 0; i < m; ++i)
{
result_list.push_back(distribution(generator));
}
std::sort(std::begin(result_list),std::end(result_list));
for (int i = 0; i < m; ++i)
{
result_list[i] += (i * k);
}
return result_list;
}
.

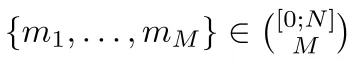
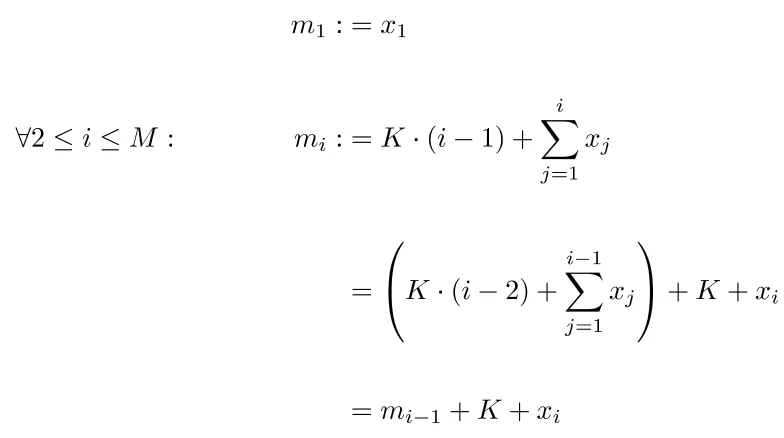
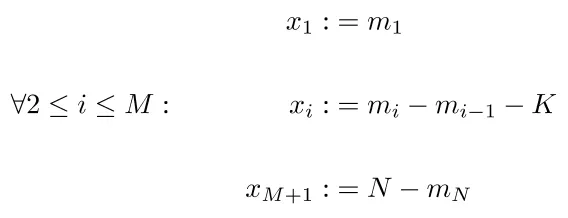
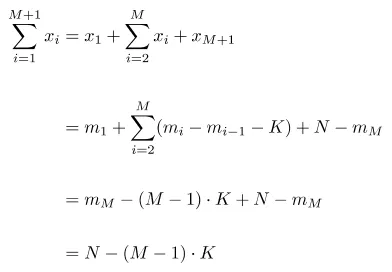
0和N - (M - 1)*K + K之间的数组进行 Fisher-Yates 洗牌,取结果数组的最后K个数字。这将给你一个大小为K的上述区间的均匀随机子集。你可以使用这个方法通过使用K子集作为N - (M - 1)*K的一元表示中的逗号来构建整数N - (M - 1)*K的K + 1组合(请参见此处以获得说明)。 - G. Bach