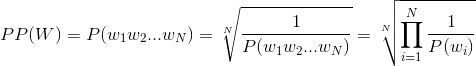我正在尝试计算我拥有的数据的困惑度。我使用的代码是:
import sys
sys.path.append("/usr/local/anaconda/lib/python2.7/site-packages/nltk")
from nltk.corpus import brown
from nltk.model import NgramModel
from nltk.probability import LidstoneProbDist, WittenBellProbDist
estimator = lambda fdist, bins: LidstoneProbDist(fdist, 0.2)
lm = NgramModel(3, brown.words(categories='news'), True, False, estimator)
print lm
但是我收到了错误信息,
File "/usr/local/anaconda/lib/python2.7/site-packages/nltk/model/ngram.py", line 107, in __init__
cfd[context][token] += 1
TypeError: 'int' object has no attribute '__getitem__'
我已经对我手头的数据执行了潜在狄利克雷分配(Latent Dirichlet Allocation),并生成了单个词和它们各自的概率(它们被归一化为数据总概率之和为1)。
我的单个词和它们的概率如下:
Negroponte 1.22948976891e-05
Andreas 7.11290670484e-07
Rheinberg 7.08255885794e-07
Joji 4.48481435106e-07
Helguson 1.89936727391e-07
CAPTION_spot 2.37395965468e-06
Mortimer 1.48540253778e-07
yellow 1.26582575863e-05
Sugar 1.49563800878e-06
four 0.000207196011781
这只是我拥有的单个字文件的片段。大约有1000行遵循相同的格式。第二列总概率和为1。
我是一名初学者程序员。这个ngram.py属于nltk包,我不知道如何纠正这个问题。我在这里有一个示例代码来自nltk文档,现在我不知道该怎么做。请帮忙指导一下,谢谢!