以下是当前流程的步骤:
- Flafka 将日志写入HDFS上的“landing zone”。
- 由Oozie调度的作业将完整的文件从landing zone复制到暂存区。
- 使用暂存区作为其位置的Hive表对暂存数据进行“模式化”处理。
- 将暂存表中的记录添加到永久Hive表中(例如,
insert into permanent_table select * from staging_table)。 - 通过在Impala中执行
refresh permanent_table,可以在Hive表中获取数据。
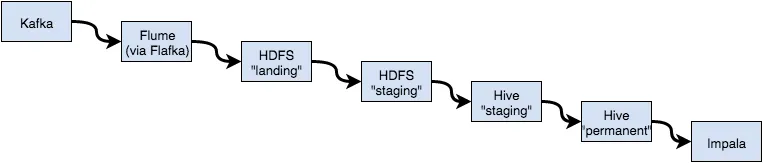
我看着我建立的过程,感觉“有点不对劲”:有太多的中间步骤影响了数据的流动。
大约20个月前,我看到了一个演示,数据从Amazon Kinesis管道流式传输,并且可以由Impala近实时查询。我不认为他们做了什么太难看/复杂的事情。从Kafka流式传输数据到Impala是否有更有效的方法(可能是可以将数据序列化为Parquet的Kafka消费者)?
我想象“将数据流式传输到低延迟SQL”一定是一个相当普遍的用例,因此我有兴趣知道其他人是如何解决这个问题的。