我有收据的图片,想要将图片中的文本内容分离出来储存。使用Amazon Rekognition可以检测图片中的文字吗?
5个回答
14
2017年11月更新:
Amazon Rekognition宣布了实时人脸识别、图像中的文字识别和改进的人脸检测。
证明如下:
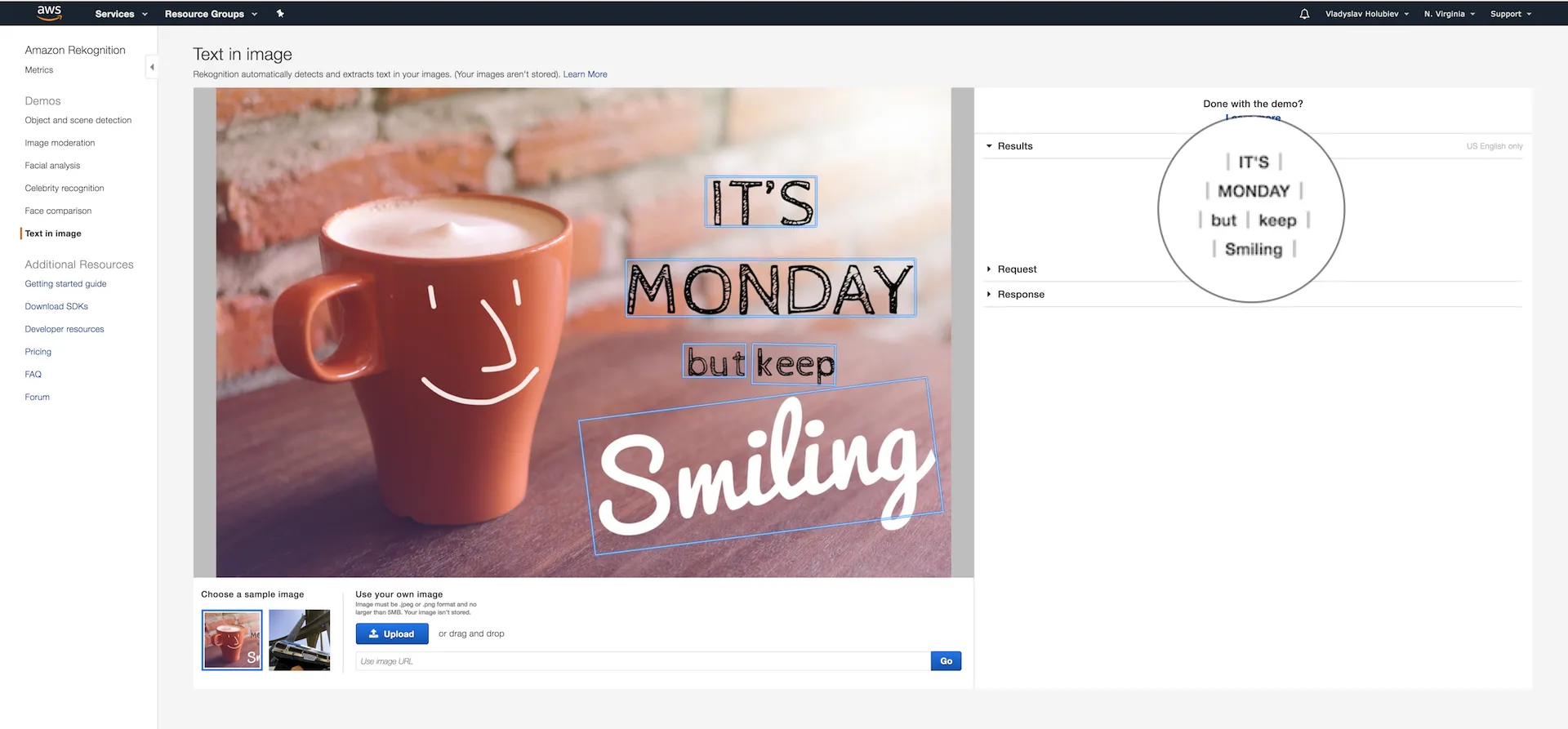
- Vlad Holubiev
3
非常正确!Amazon Rekognition 图像中的文本 "可以检测图像中的文本并将其转换为机器可读的文本"。但是,它无法进行全页OCR。 - John Rotenstein
1AWS Rekognition OCR 的字数限制为50个词。 :( - Vingtoft
@Vingtoft 对我来说也是个惊喜,所以Tesseract+Lambda来拯救 - https://twitter.com/vladholubiev/status/1022607436274970624 - Vlad Holubiev
6
不,Amazon Rekognition不能提供光学字符识别(OCR)。
截至撰写本文的时间(2017年3月),它只提供以下功能:
- 物体和场景检测
- 面部分析
- 人脸比对
- 人脸识别
没有AWS提供OCR服务的。您需要使用第三方产品。
- John Rotenstein
1
2截至2018年2月,OCR功能现在可以在Amazon Web Services中进行演示,例如在https://console.aws.amazon.com/rekognition/home?region=us-east-1#/text-detection。 - xke
3
亚马逊不提供OCR API。你可以使用Google Cloud Vision API进行文本识别,但这需要支付3.5美元/1000张图片的费用。要测试Google的API,请打开下面的链接并将以下代码粘贴到右侧的测试请求正文中。
https://cloud.google.com/vision/docs/reference/rest/v1/images/annotate
{
"requests": [
{
"image": {
"source": {
"imageUri": "JPG_PNG_GIF_or_PDF_url"
}
},
"features": [
{
"type": "DOCUMENT_TEXT_DETECTION"
}
]
}
]
}
- Kareem
2
您可能会通过Amazon Textract获得更好的结果,尽管它目前仅在有限预览中提供。
使用AWS JS SDK和Rekognition可以检测图像中的文本,但您的结果可能会有所不同。
在这个答案中,可以看到更多使用NodeJS与Rekognition的示例。
使用AWS JS SDK和Rekognition可以检测图像中的文本,但您的结果可能会有所不同。
/* jshint esversion: 6, node:true, devel: true, undef: true, unused: true */
// Import libs.
const AWS = require('aws-sdk');
const axios = require('axios');
// Grab AWS access keys from Environmental Variables.
const { S3_ACCESS_KEY, S3_SECRET_ACCESS_KEY, S3_REGION } = process.env;
// Configure AWS with credentials.
AWS.config.update({
accessKeyId: S3_ACCESS_KEY,
secretAccessKey: S3_SECRET_ACCESS_KEY,
region: S3_REGION
});
const rekognition = new AWS.Rekognition({
apiVersion: '2016-06-27'
});
const TEXT_IMAGE_URL = 'https://loremflickr.com/g/320/240/text';
(async url => {
// Fetch the URL.
const textDetections = await axios
.get(url, {
responseType: 'arraybuffer'
})
// Convert to base64 Buffer.
.then(response => new Buffer(response.data, 'base64'))
// Pass bytes to SDK
.then(bytes =>
rekognition
.detectText({
Image: {
Bytes: bytes
}
})
.promise()
)
.catch(error => {
console.log('[ERROR]', error);
return false;
});
if (!textDetections) return console.log('Failed to find text.');
// Output the raw response.
console.log('\n', 'Text Detected:', '\n', textDetections);
// Output to Detected Text only.
console.log('\n', 'Found Text:', '\n', textDetections.TextDetections.map(t => t.DetectedText));
})(TEXT_IMAGE_URL);
在这个答案中,可以看到更多使用NodeJS与Rekognition的示例。
- jgraup
1
public async Task<List<string>> IdentifyText(string filename)
{
// Using USWest2, not the default region
AmazonRekognitionClient rekoClient = new AmazonRekognitionClient("Access Key ID", "Secret Access Key", RegionEndpoint.USEast1);
Amazon.Rekognition.Model.Image img = new Amazon.Rekognition.Model.Image();
byte[] data = null;
using (FileStream fs = new FileStream(filename, FileMode.Open, FileAccess.Read))
{
data = new byte[fs.Length];
fs.Read(data, 0, (int)fs.Length);
}
img.Bytes = new MemoryStream(data);
DetectTextRequest dfr = new DetectTextRequest();
dfr.Image = img;
var outcome = rekoClient.DetectText(dfr);
return outcome.TextDetections.Select(x=>x.DetectedText).ToList();
}
- Amit Shukla
1
请在您的答案中添加注释,解释您的代码。 - Irreducible
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
- 相关问题
- 5 AWS Rekognition出现InvalidS3Exeption错误
- 5 AWS Rekognition检测标签无效图像编码错误
- 4 亚马逊机器学习用于情感分析
- 4 使用AWS Rekognition检测活体是否真实
- 3 亚马逊MWS API用于更新库存
- 4 能否使用谷歌的视觉API或亚马逊的Rekognition获得对象的计数?
- 4 如何使用AWS Rekognition在Swift 3中检测图像标签和人脸
- 6 亚马逊 Rekognition API - S3 元数据问题
- 3 如何使用AWS Rekognition服务和Node.js检测人脸
- 7 我该如何在Android Studio中使用Amazon Rekognition AWS检测人脸?