我可以使用动态规划的正确方式来解决这个问题,但我无法想出如何在指数时间内完成。
我想找到两个字符串之间的最长公共子序列。 注意:我指的是子序列而不是子字符串,即组成序列的符号不需要是连续的。
我可以使用动态规划的正确方式来解决这个问题,但我无法想出如何在指数时间内完成。
我想找到两个字符串之间的最长公共子序列。 注意:我指的是子序列而不是子字符串,即组成序列的符号不需要是连续的。
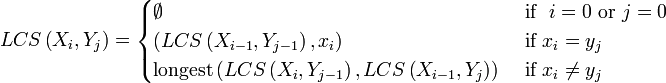
编辑
伪代码(类似Python):
def lcs(s1, s2):
if len(s1)==0 or len(s2)==0: return 0
if s1[0] == s2[0]: return 1 + lcs(s1[1:], s2[1:])
return max(lcs(s1, s2[1:]), lcs(s1[1:], s2))
字符串A和字符串B。一个递归算法,也许有点天真,但它很简单:
查看A的第一个字母。这要么在一个公共序列中,要么不在。考虑“不在”的选项时,我们会去掉第一个字母并进行递归调用。考虑“在公共序列中”的选项时,我们也会去掉它,并从B的开头开始削减,直到包括B中相同的字母。一些伪代码:
def common_subsequences(A,B, len_subsequence_so_far = 0):
if len(A) == 0 or len(B) == 0:
return
first_of_A = A[0] // the first letter in A.
A1 = A[1:] // A, but with the first letter removed
common_subsequences(A1,B,len_subsequence_so_far) // the first recursive call
if(the_first_letter_of_A_is_also_in_B):
Bn = ... delete from the start of B up to, and including,
... the first letter which equals first_of_A
common_subsequences(A1,Bn, 1+len_subsequence_so_far )
min(len(A), len(B))+len_subsequence_so_far小于目前为止找到的最长长度)。for i=n to 0
for all length i subsequences s of a
if s is a subsequence of b
return s
Generate all subsequences of `array1` and `array2`.
for each subsequence of `array1` as s1
for each subsequece of `array2` as s2
if s1 == s2 //check char by char
if len(s1) > currentMax
currentMax = len(s1)
for i = 0; i < 2^2; i++;
这绝对不是最优解。它甚至没有尝试过。然而,问题是关于非常低效的算法,所以我提供了一个。
本质上,如果您不使用动态规划范例,则会达到指数时间。这是因为,通过不存储部分值,您会多次重新计算部分值。
int lcs(char[] x, int i, char[] y, int j) {
if (i == 0 || j == 0) return 0;
if (x[i - 1] == y[j - 1]) return lcs(x, i - 1, y, j - 1) + 1;
return Math.max(lcs(x, i, y, j - 1), lcs(x, i - 1, y, j));
}
print(lcs(x, x.length, y, y.length);
lcs("ABCD", "AFDX")
/ \
lcs("ABC", "AFDX") lcs("ABCD", "AFD")
/ \ / \
lcs("AB", "AFDX") lcs("AXY", "AFD") lcs("ABC", "AFD") lcs("ABCD", "AF")
最坏情况是LCS的长度为0,这意味着没有共同的子序列。在这种情况下,所有可能的子序列都会被检查,而且有O(2^n)个子序列。