我有一个关于一种mean()计算的问题。我使用带有两个标识符“ID”和“year”的面板数据集(使用plm包)。
我想计算变量“y”的组内平均值,但忽略计算的第一年的条目,然后仅在用于计算的年份中填充计算出的平均值。换句话说,我想在这个变量的每个ID的第一个条目中有NA。
面板数据是不平衡的,因此人们会在不同的时间点来来去去。一些人从一开始就一直留到结束,对于其他人,我只有三年的数据。
library(tidyverse)
library(plm)
ID <- c("a","a","a","a","a","b","b","b","b","c","c","c")
y <- c(9,2,5,3,3,9,1,2,3,9,2,5)
year<- c(2001,2002,2003,2004,2005,2001,2002,2003,2004,2002,2003,2004)
dt <- data.frame(ID,y,year)
dt <- pdata.frame(dt, index = c("ID","year"))
我首先尝试了一个过滤器来处理周期,就像这样:
dt <- dt %>% group_by(ID) %>%
filter(year %in% first(year)+1:last(year)) %>%
mutate(mean.y = mean(y))
但是那样做是不行的,说实话我并不感到惊讶,但我希望你知道我想要实现什么。最终结果应该像这样:
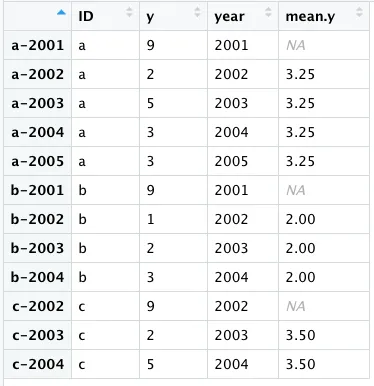
看看变量 y 的第一个条目" a-2001" 的值为 9 是如何被忽略的,以便它不会影响各个 a 的其他 y 条目的平均值 (2+5+3+3)/4。
希望你们能理解,非常感谢任何帮助。再见。
is.na<-`(mean.y, 1L)吗? - Alvaro Moralesmean.y相同,只是第一个元素 (1L) 被替换为NA值。例如,\is.na<-`(c(1,2,3), 1L)将返回NA 2 3`。 - ekoam