我能成功从所有pdf页面提取文本,但无法生成结构化数据。如果有人遇到这方面的专业问题,请给予指导。
代码:
结构化输出。但问题是条形码别名产品代码的数量未出现。
代码:
package pdfboxreadfromfile;
import java.awt.geom.Rectangle2D;
import java.io.File;
import java.io.IOException;
import java.util.List;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.pdmodel.PDDocumentCatalog;
import org.apache.pdfbox.pdmodel.PDPage;
import org.apache.pdfbox.pdmodel.interactive.form.PDAcroForm;
import org.apache.pdfbox.pdmodel.interactive.form.PDField;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.pdfbox.text.PDFTextStripperByArea;
public class PDFBoxReadFromFile {
public static void main(String[] args) {
try {
File file = new File("C:/ma.pdf");
PDDocument doc = PDDocument.load(file);
PDFTextStripper pdfTextStripper = new PDFTextStripper();
pdfTextStripper.setSortByPosition(true);
pdfTextStripper.setStartPage(1);
pdfTextStripper.setEndPage(6);
String text = pdfTextStripper.getText(doc);
System.out.println(text);
doc.close();
} catch (IOException e) {
e.printStackTrace();
}
}
输出:
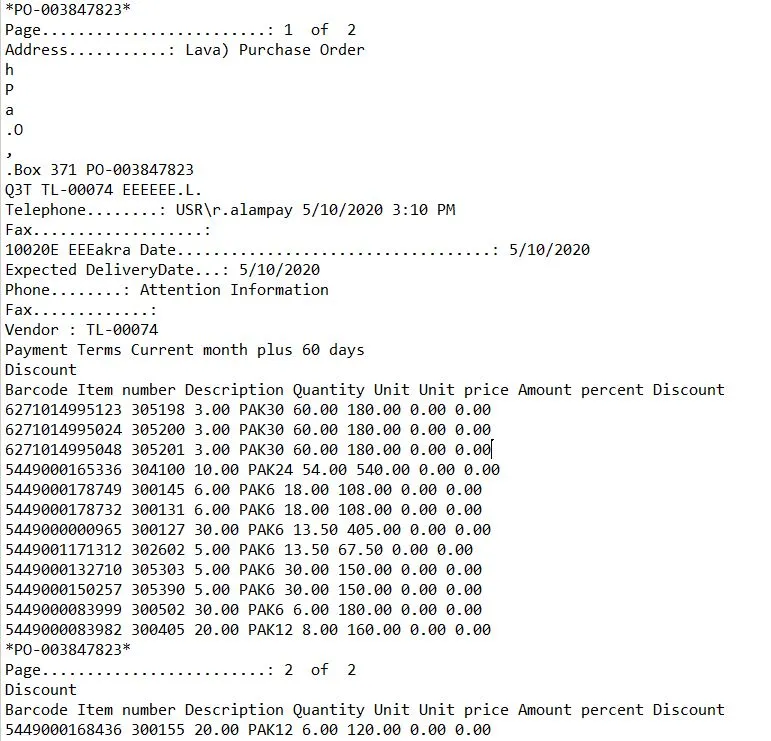
PDF文件看起来像这样。
第1页:
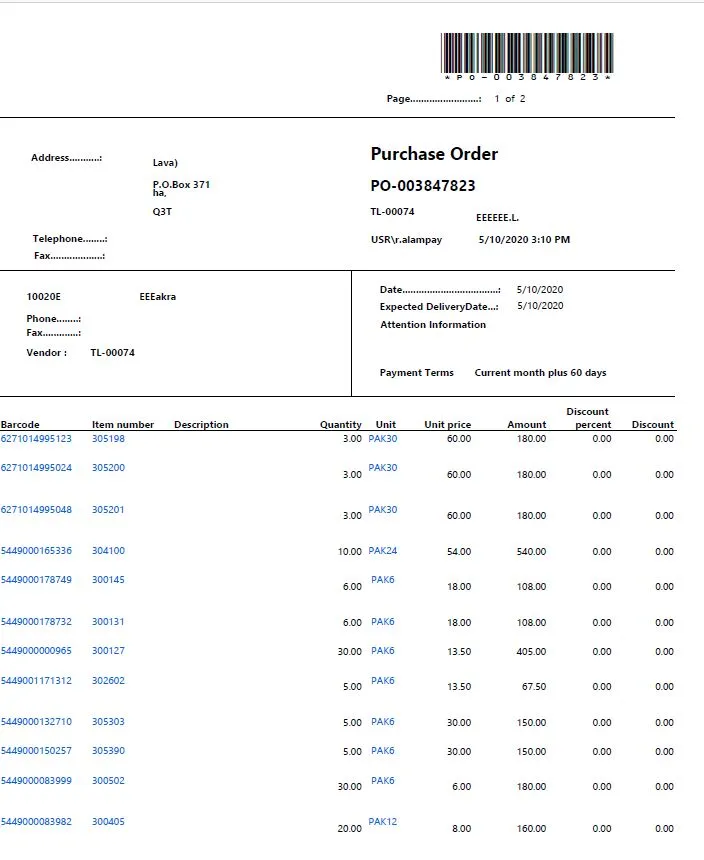
预期的页眉文字仅供参考,不需要打印出来。
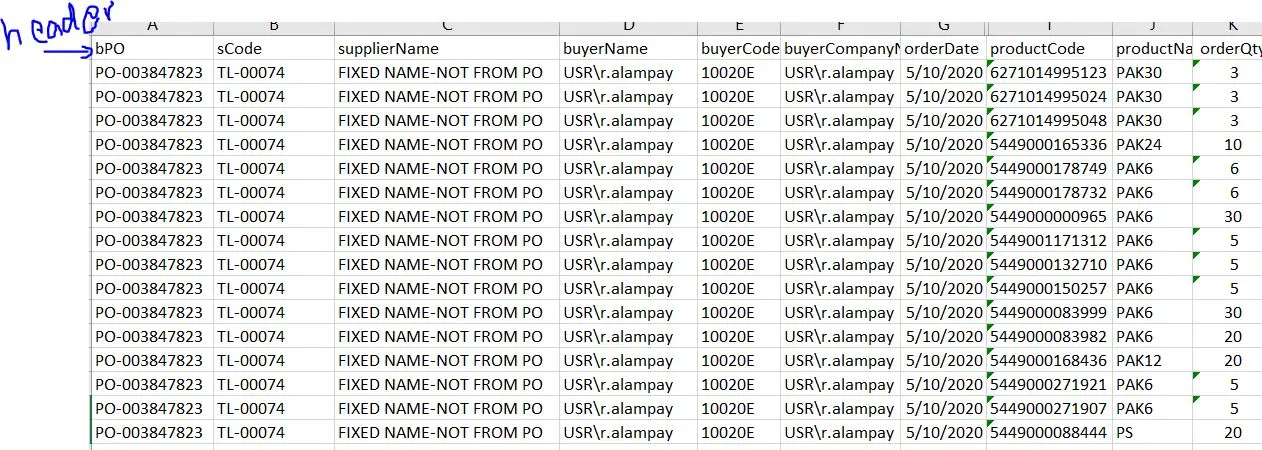
尝试了以下方法:
Pattern p = Pattern.compile("PO...........*?");
Pattern p1 = Pattern.compile("Vendor...........");
Pattern p2 = Pattern.compile("100.....*?");
Pattern p4 = Pattern.compile("Date...............................................*?");
Pattern p5 = Pattern.compile("62...........3*?");
Pattern p6 = Pattern.compile("62710149950...*?");
Pattern p7 = Pattern.compile("627101499504..*?");
Matcher m = p.matcher(text);
Matcher m1 = p1.matcher(text);
Matcher m2 = p2.matcher(text);
Matcher m4 = p4.matcher(text);
Matcher m5 = p5.matcher(text);
Matcher m6 = p6.matcher(text);
Matcher m7 = p7.matcher(text);
m.find();
m1.find();
m2.find();
m4.find();
m5.find();
m6.find();
m7.find();
System.out.println(m.group(0) + "|" + m1.group(0) + "|" + m2.group(0) + "|" + m2.group(0) + "|" + "MAC" + "|" + m4.group(0) + "|" + m5.group(0) + "|");
System.out.println(m.group(0) + "|" + m1.group(0) + "|" + m2.group(0) + "|" + m2.group(0) + "|" + "MAC" + "|" + m4.group(0) + "|" + m6.group(0) + "|");
System.out.println(m.group(0) + "|" + m1.group(0) + "|" + m2.group(0) + "|" + m2.group(0) + "|" + "MAC" + "|" + m4.group(0) + "|" + m7.group(0) + "|");
结构化输出。但问题是条形码别名产品代码的数量未出现。