我决定将我的win32 c++应用程序转换为Unicode版本,但是当我使用它时,阿拉伯语、中文和日语出现了无法阅读的字母...
首先:
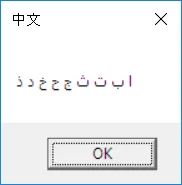
如果我不使用Unicode,在编辑框和窗口标题中可以正确显示阿拉伯语:
HWND hWnd = CreateWindowEx(WS_EX_CLIENTEDGE, "Edit", "ا ب ت ث ج ح خ د ذ", WS_CHILD | WS_VISIBLE | WS_BORDER | ES_MULTILINE, 10, 10, 300, 200, hWnd, (HMENU)100, GetModuleHandle(NULL), NULL);
SetWindowText(hWnd, "صباح الخير");
输出看上去正常且工作良好!(不含Unicode)。
- 带有Unicode:
我在包含标题之前添加了:
#define UNICODE
#include <windows.h
现在在窗口过程中:
case WM_CREATE:{
HWND hEdit = CreateWindowExW(WS_EX_CLIENTEDGE, L"Edit", L"ا ب ت ث ج ح خ د ذ", WS_CHILD | WS_VISIBLE | WS_BORDER | ES_MULTILINE, 10, 10, 300, 200, hWnd, (HMENU)100, GetModuleHandle(NULL), NULL);
// Even I send message to change text but I get unreadable characters!
}
break;
case WM_LBUTTONDBLCLK:{
SendDlgItemMessageW(hWnd, 100, WM_SETTEXT, 0, (LPARAM)L"السلام عليكم"); // Get unreadable characters also
}
break;
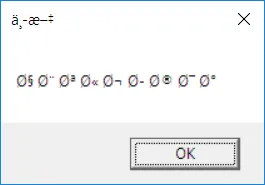
正如您所看到的,使用Unicode时控件无法正确显示阿拉伯字符。
- 重要的是:在创建控件后,我手动使用
backspace删除内容。现在如果我手动输入阿拉伯文本,则会成功正确显示?!!!但是为什么使用函数呢?例如SetWindowTextW()?
请帮忙解决。谢谢。
WM_SETFONT为编辑控件分配一个启用Unicode的字体。 - Remy Lebeau