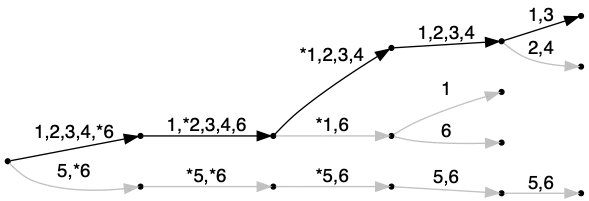
假设我有一个长度相等的元组列表,其中每个元素都是整数或者是一个"星号",例如:
在这种情况下,元素1和3重叠,2和4重叠,5和6重叠。
有没有一种方法可以在比传统方法更短的时间内确定是否存在重叠(我实际上不需要所有的重叠,只需回答是否存在至少一个)?传统方法是将所有可能的对进行检查(自然地是O(n^2))。
来自评论的澄清:
- 上述的n是行数。这是可能会变得很大的事情。为了解决这个问题,假设列数相对较小,比如不超过20。 - “星号”代表确切的一个元素。
[
(1, 2, *, 4, 5),
(1, *, 3, 4, 6),
(1, *, 3, 4, 5),
(1, 2, 3, 4, 6),
(4, *, *, 5, 6),
(*, *, 1, 5, 6)
]
在这种情况下,元素1和3重叠,2和4重叠,5和6重叠。
有没有一种方法可以在比传统方法更短的时间内确定是否存在重叠(我实际上不需要所有的重叠,只需回答是否存在至少一个)?传统方法是将所有可能的对进行检查(自然地是O(n^2))。
来自评论的澄清:
- 上述的n是行数。这是可能会变得很大的事情。为了解决这个问题,假设列数相对较小,比如不超过20。 - “星号”代表确切的一个元素。