在这个答案的底部有一些基准测试代码,因为您明确表示您对性能感兴趣而不是任意避免for循环。
实际上,我认为for循环可能是最有效的选择。自从引入了“新”的(2015b)JIT引擎以来(
source),for循环并不是本质上缓慢的--事实上它们在内部进行了优化。
您可以从基准测试中看到,由ThomasIsCoding
here提供的mat2cell选项非常缓慢...
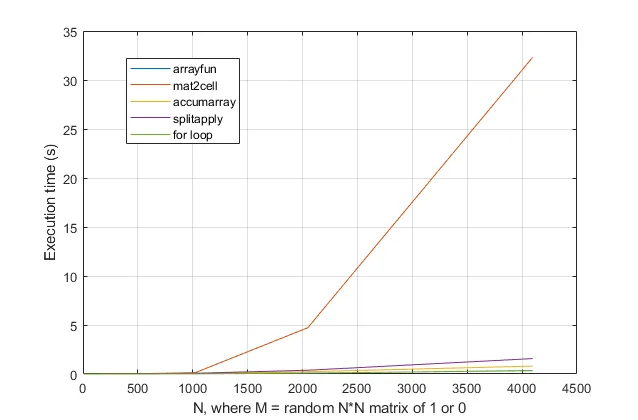
如果我们删除那行代码以使比例更清晰,那么我的
splitapply方法就会变得相当慢,obchardon的
accumarray选项稍微好一些,但最快(且可比较)的选项要么是使用
arrayfun(如Thomas所建议的),要么是使用
for循环。请注意,对于大多数用例,
arrayfun基本上是一个伪装成
for循环的函数,因此这不是一个令人惊讶的平局!

我建议您使用
for 循环以提高代码可读性和最佳性能。
编辑:
如果我们假设循环是最快的方法,我们可以在 find 命令周围进行一些优化。
具体而言:
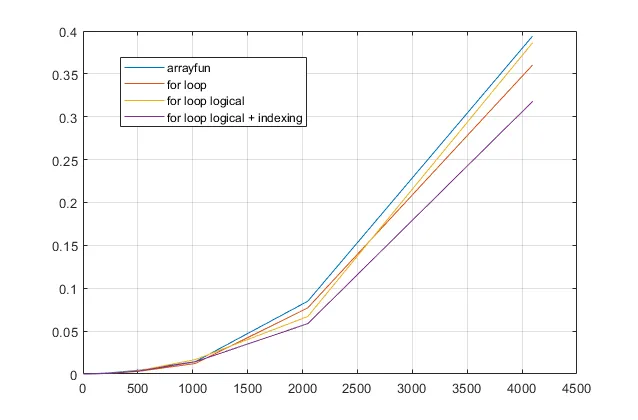
使 M 逻辑。如下图所示,对于相对较小的 M,这可能更快,但与类型转换相比,对于大型 M,速度较慢。
使用逻辑 M 来索引数组 1:size(M,2),而不是使用 find。这避免了循环中最慢的部分(find 命令),并且超过了类型转换开销,使其成为最快的选项。
以下是我对最佳性能的建议:
function A = f_forlooplogicalindexing( M )
M = logical(M);
k = 1:size(M,2);
N = size(M,1);
A = cell(N,1);
for r = 1:N
A{r} = k(M(r,:));
end
end
我已将此添加到以下基准测试中,以下是循环方式方法的比较:
基准测试代码:
rng(904);
p = 2:12;
T = NaN( numel(p), 7 );
for ii = p
N = 2^ii;
M = randi([0,1],N);
fprintf( 'N = 2^%.0f = %.0f\n', log2(N), N );
f1 = @()f_arrayfun( M );
f2 = @()f_mat2cell( M );
f3 = @()f_accumarray( M );
f4 = @()f_splitapply( M );
f5 = @()f_forloop( M );
f6 = @()f_forlooplogical( M );
f7 = @()f_forlooplogicalindexing( M );
T(ii, 1) = timeit( f1 );
T(ii, 2) = timeit( f2 );
T(ii, 3) = timeit( f3 );
T(ii, 4) = timeit( f4 );
T(ii, 5) = timeit( f5 );
T(ii, 6) = timeit( f6 );
T(ii, 7) = timeit( f7 );
end
plot( (2.^p).', T(2:end,:) );
legend( {'arrayfun','mat2cell','accumarray','splitapply','for loop',...
'for loop logical', 'for loop logical + indexing'} );
grid on;
xlabel( 'N, where M = random N*N matrix of 1 or 0' );
ylabel( 'Execution time (s)' );
disp( 'Done' );
function A = f_arrayfun( M )
A = arrayfun(@(r) find(M(r,:)),1:size(M,1),'UniformOutput',false);
end
function A = f_mat2cell( M )
[i,j] = find(M.');
A = mat2cell(i,arrayfun(@(r) sum(j==r),min(j):max(j)));
end
function A = f_accumarray( M )
[val,ind] = ind2sub(size(M),find(M.'));
A = accumarray(ind,val,[],@(x) {x});
end
function A = f_splitapply( M )
[r,c] = find(M);
A = splitapply( @(x) {x}, c, r );
end
function A = f_forloop( M )
N = size(M,1);
A = cell(N,1);
for r = 1:N
A{r} = find(M(r,:));
end
end
function A = f_forlooplogical( M )
M = logical(M);
N = size(M,1);
A = cell(N,1);
for r = 1:N
A{r} = find(M(r,:));
end
end
function A = f_forlooplogicalindexing( M )
M = logical(M);
k = 1:size(M,2);
N = size(M,1);
A = cell(N,1);
for r = 1:N
A{r} = k(M(r,:));
end
end
for循环?对于这个问题,在现代版本的MATLAB中,我强烈怀疑使用for循环是最快的解决方案。如果你有性能问题,我怀疑你正在根据过时的建议寻找解决方案而不是正确的地方。 - Will1?我不会期望一个find循环需要花费接近 30 秒的时间,对于任何小到足以适应物理内存的东西。 - Will