目前我正在尝试在Neo4j 2.2.2上运行此查询。
在发布此文章时,我们还没有将任何节点标记为我们最近从Neo4j 1.x升级。因此,我们无法使用USING子句选项。
我尝试使用索引,但最终只得到了全表扫描。
START pfComp=node:Company('id:2403226') , ptComp=node:Company('id:1946633')
OPTIONAL MATCH
(pfComp)<-[c:CHILD_OF*]-(cfComp)
WITH collect(id(cfComp)) as cfCompIds, ptComp, pfComp
OPTIONAL MATCH
(ptComp)<-[c2:CHILD_OF*]-(ctComp)
WITH cfCompIds, collect(id(ctComp)) AS ctCompIds
MATCH
(fComp) -[fR:PARTICIPATES_IN]-> cdeals <-[tR:PARTICIPATES_IN]-(tComp)
WHERE
(fComp.id = 2403226 or id(fComp) in cfCompIds) and
(tComp.id = 1946633 or id(tComp) in ctCompIds)
RETURN fComp, tComp, cdeals
密码版本: CYPHER 2.2,计划器: COST。在79128毫秒内,共计1305292个数据库命中。
非常感谢您的任何帮助。
以下是完整的profile命令输出。
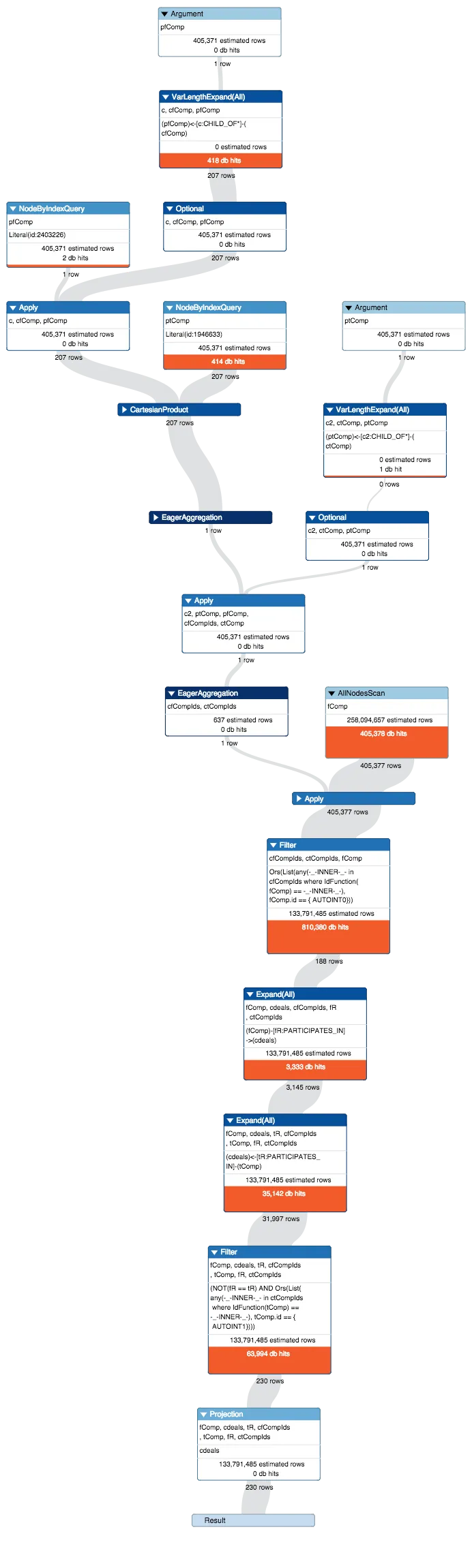
查询的开始部分执行得很快:
profile START pfComp=node:Company('id:2403226') , ptComp=node:Company('id:1946633')
OPTIONAL MATCH
(pfComp)<-[c:CHILD_OF*]-(cfComp)
WITH collect(id(cfComp)) as cfCompIds, ptComp, pfComp
OPTIONAL MATCH
(ptComp)<-[c2:CHILD_OF*]-(ctComp)
return cfCompIds, collect(id(ctComp)) AS ctCompIds
密码版本:CYPHER 2.2,计划程序:COST。582毫秒内总共有836个数据库命中。
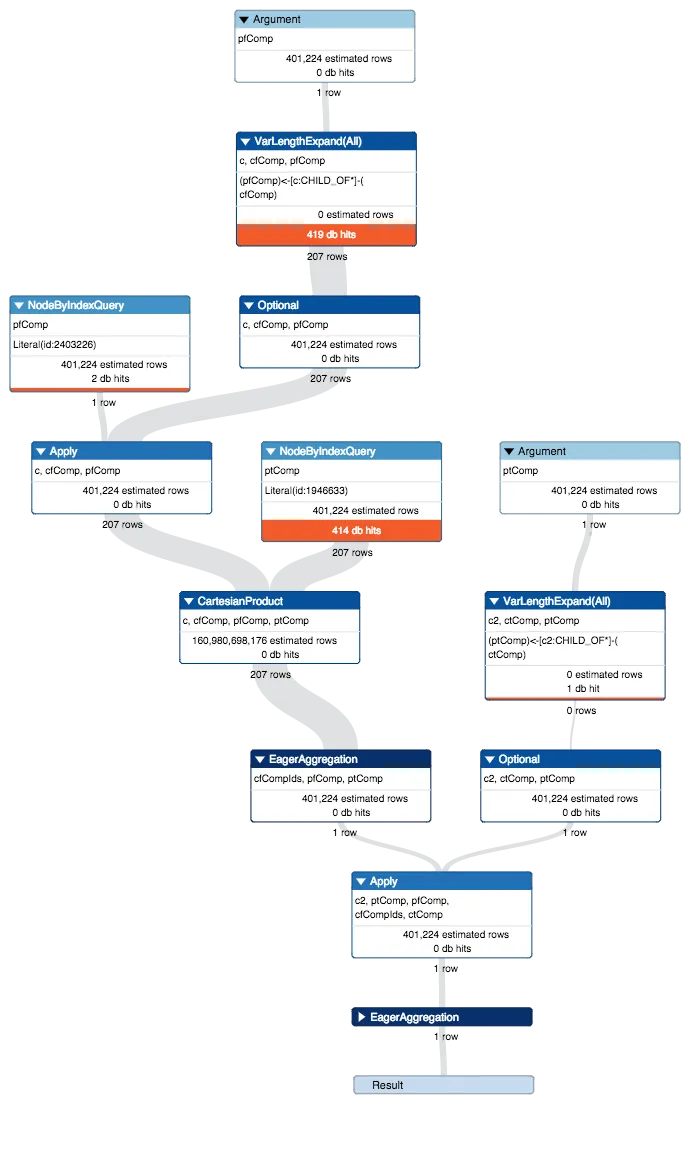
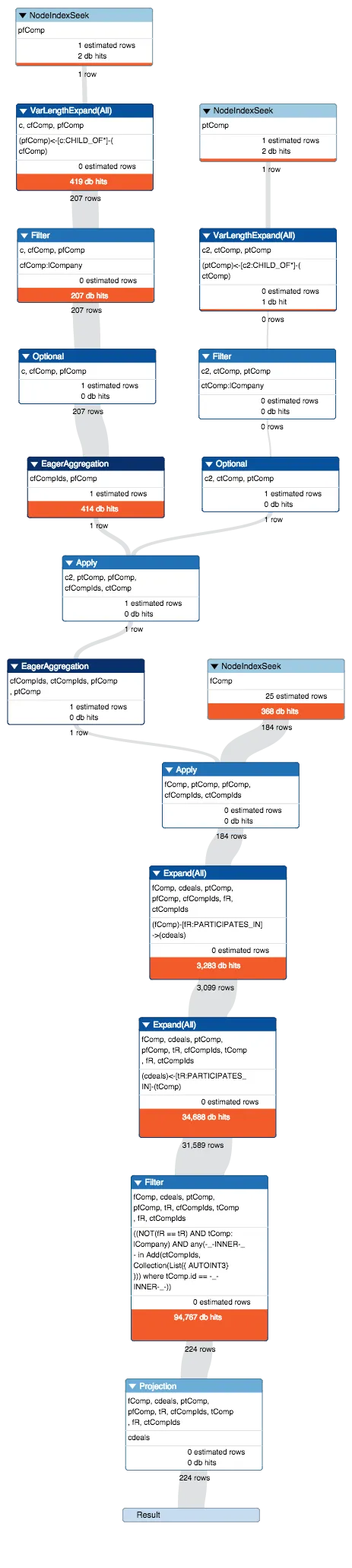
OPTIONAL MATCH (ptComp)<-[c2:CHILD_OF*]-(ctComp)。 - Michael Hunger结果: Cypher版本:CYPHER 2.2,规划器:COST。582毫秒内共有836个数据库命中。 - Ted Gulesserian