我有如下的C程序:
int main()
{
int c[10] = {0, 0, 0, 0, 0, 0, 0, 0, 1, 2};
return c[0];
}
使用gcc并采用-S指令编译后,得到以下汇编代码:
.file "array.c"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $0, -48(%rbp)
movl $0, -44(%rbp)
movl $0, -40(%rbp)
movl $0, -36(%rbp)
movl $0, -32(%rbp)
movl $0, -28(%rbp)
movl $0, -24(%rbp)
movl $0, -20(%rbp)
movl $1, -16(%rbp)
movl $2, -12(%rbp)
movl -48(%rbp), %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 4.4.5 20110214 (Red Hat 4.4.5-6)"
.section .note.GNU-stack,"",@progbits
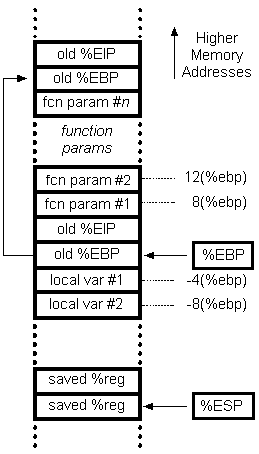
我不明白的是为什么早期的数组元素距离bp更远?它似乎几乎是将数组元素按相反的顺序放置。
此外,为什么gcc没有使用push而是使用movl来将数组元素推入堆栈?
不同的观点
将数组作为模块的静态变量移动到全局命名空间中:
.file "array.c"
.data
.align 32
.type c, @object
.size c, 40
c:
.long 0
.long 0
.long 0
.long 0
.long 0
.long 0
.long 0
.long 0
.long 1
.long 2
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl c(%rip), %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 4.4.5 20110214 (Red Hat 4.4.5-6)"
.section .note.GNU-stack,"",@progbits
使用下面这个 C 程序:
static int c[10] = {0, 0, 0, 0, 0, 0, 0, 0, 1, 2};
int main()
{
return c[0];
}
这并没有提供更多关于堆栈的见解。但是看到使用略有不同语义的汇编产生的不同输出结果还是很有趣的。
 我认为编译器完全可以使用一系列
我认为编译器完全可以使用一系列
-S(将汇编生成为文本),而不是-Os(为大小进行优化)。此汇编代码似乎是在没有优化的情况下生成的;无论使用哪个级别的-O,我都看不到任何数组存储。 - zwol