我被委托生成一定数量的数据缓存未命中和指令缓存未命中。我已经顺利处理了数据缓存部分。
所以我现在需要生成指令缓存未命中,但我不知道是什么原因导致的。有人可以建议一种生成方法吗?
我在Linux上使用GCC。
所以我现在需要生成指令缓存未命中,但我不知道是什么原因导致的。有人可以建议一种生成方法吗?
我在Linux上使用GCC。
正如其他人已经解释过的那样,指令缓存未命中与数据缓存未命中在概念上是相同的——指令不在缓存中。这是因为处理器的程序计数器(PC)跳转到一个尚未加载到缓存中的位置,或者由于缓存已满,该缓存行被选择用于清除(通常是最近最少使用的缓存行)。
手动生成足够多的代码以强制发生指令未命中比强制发生数据缓存未命中略微困难。
一种获得大量代码但不费吹灰之力的方法是编写一个生成源代码的程序。
例如,编写一个生成具有巨大switch语句的函数的程序(在C语言中)[警告:未经测试]:
printf("void bigswitch(int n) {\n switch (n) {");
for (int i=1; i<100000; ++i) {
printf(" case %d: n += %d;\n", n, n+i/2);
}
printf(" }\n return n;}\n");
case:语句的数量来“调整”函数的大小。您还可以通过谨慎选择bigswitchNNN()的参数来选择打中的缓存行数。case %d: bigarray[%d] += %d;\n" 并清空 两个 缓存。 - Mooing Duck0x90(NOPs)和一个终止符0xC3(RET)填充数组,并使用函数指针来执行该数组。在执行之前,可能需要将底层内存标记为可执行的(在Windows上为VirtualProtect(),在Linux上为mprotect())。 - Alexey Frunze导致指令缓存未命中的另一种方法是编写(或生成)大量非常大的函数,使得您的代码段变得庞大。 然后从一个函数狂呼另一个函数,这样从CPU的角度来看,您正在内存中执行疯狂的GOTO操作。
mprotect或等效功能... - R.. GitHub STOP HELPING ICE即兴而未经测试,x86汇编函数的整体内容可能如下所示:
myAsmFunc1:
nop
nop
nop # ...exactly enough NOPs to fill one "way" of the cache
nop # minus however many bytes a "ret" instruction is (1?)
.
.
.
nop
ret # return to the caller
myAsmFunc1:
nop
nop
nop # ...exactly enough NOPs to fill one "way" of the cache
. # minus 4 bytes for the "blr" instruction. Note that
. # on PPC, all instructions (including NOP) are 4 bytes.
.
nop
blr # return to the caller
extern "C" void myAsmFunc1(); // Prototype for calling from C++ code
void myAsmFunc1(void); /* Prototype for calling from C code */
根据您的编译器,您可能需要在汇编代码本身的函数名前加下划线(但不需要在您的C++/C函数原型中加下划线)。
case:中使用非常简单的语句,例如n += 16bitint;,那么可以使每个case:的大小规则和可预测,并且控制函数的大小。 - gbulmer对于指令高速缓存未命中,您需要执行远离的代码段。将逻辑分割成多个函数调用是一种方法。
我正在使用ARM M7 CPU进行类似的实验,以探究Playdate硬件的能力,并尝试确认指令缓存的大小和行为。
我做了与@phonetagger's answer类似的事情,使用内联汇编创建已知大小的函数。我认为最好生成许多小函数,因为没有分支的大函数将允许分支预测逻辑无误地工作,并且非常有效地预加载指令缓存。
我的当前测试场景基于一个包含256个函数指针的表格,每个指针指向一个64字节长或两个缓存行(在ARM M7的情况下)的函数。总共,这256个函数占用256 x 64 = 16K的内存,这是4K指令缓存大小的四倍 - 基于data sheet,我认为这符合Playdate中的部分,该数据表还表明指令缓存是2路关联的。
我的测试策略是反复运行一些功能,这些功能加起来达到已知的内存量,并变化覆盖的内存量以评估当所有东西都适合缓存和不适合缓存时的时间。例如,要测试2K指令内存,我需要运行2048/64 = 32个函数,因此我的代码将是:
int n = 32;
for (int calls = 0; calls < 100000; calls++)
{
functable[calls%n]();
}
我进行了100,000次调用,以确保它需要足够长的时间才能获得一致的计时。显然,循环逻辑也在运行,但这只应该消耗几个缓存行,因此不应该对结果产生太大影响。
我重复上述测试,n从1到256运行,因此测试64字节到16K指令的时间。以下是结果:
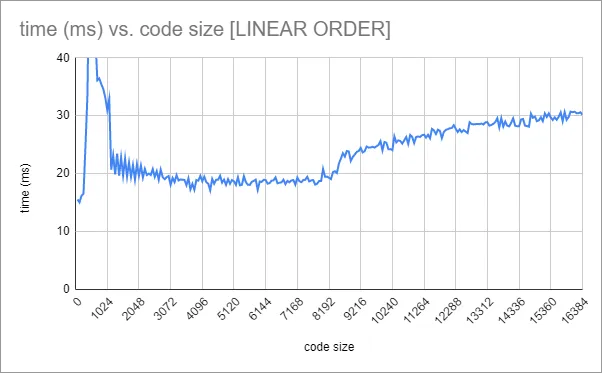
我对以下几点感到困惑:
我所有的函数都是按照线性方式排列在内存中,所以我想知道CPU是否正在预取后续函数,因此我尝试以随机顺序调用函数。在开始计时循环之前,我使用插入排序来随机化函数表中前n个条目。结果非常相似,但令人惊讶的是,时间花费的早期峰值 - 虽然仍然存在 - 比线性顺序情况下要低。
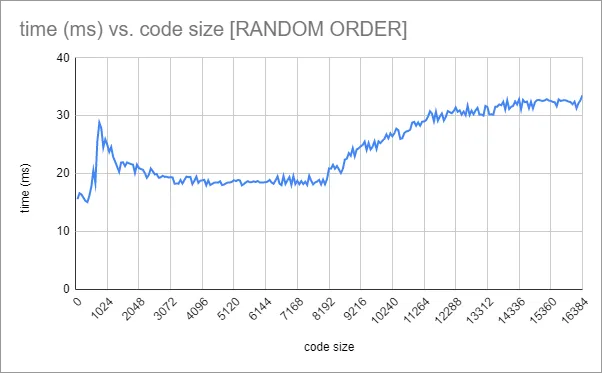
总之,我认为我的过程相当可靠,但我对结果感到困惑,并希望获得额外的见解。