我正在使用一个Java scrypt library来进行密码存储。在加密时,它需要一个
请问有人对此有什么建议吗?该库本身列出了N = 16384、r = 8和p = 1,但我不知道这是强还是弱,或者是什么意思。
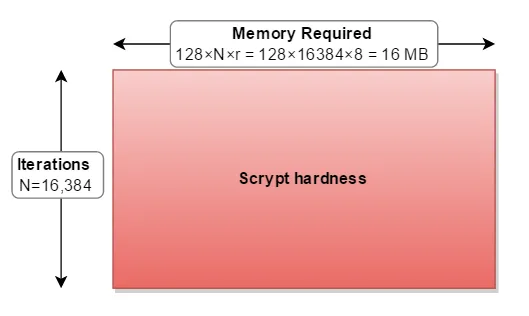
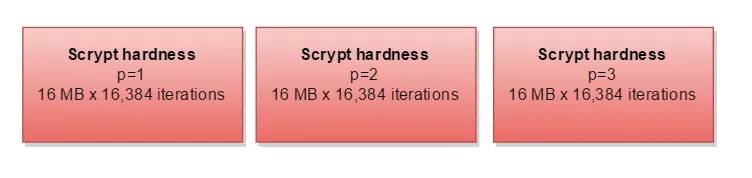
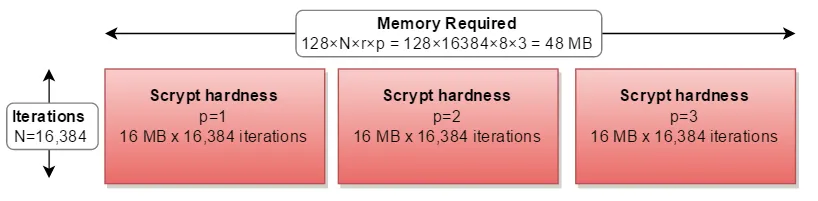
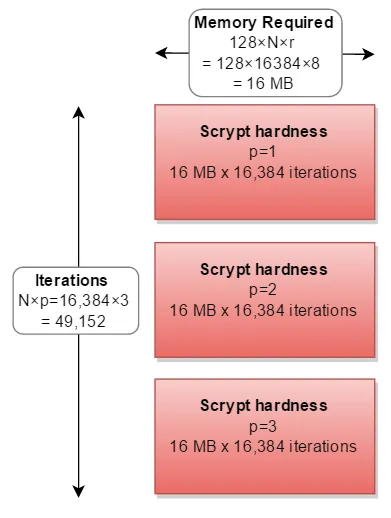
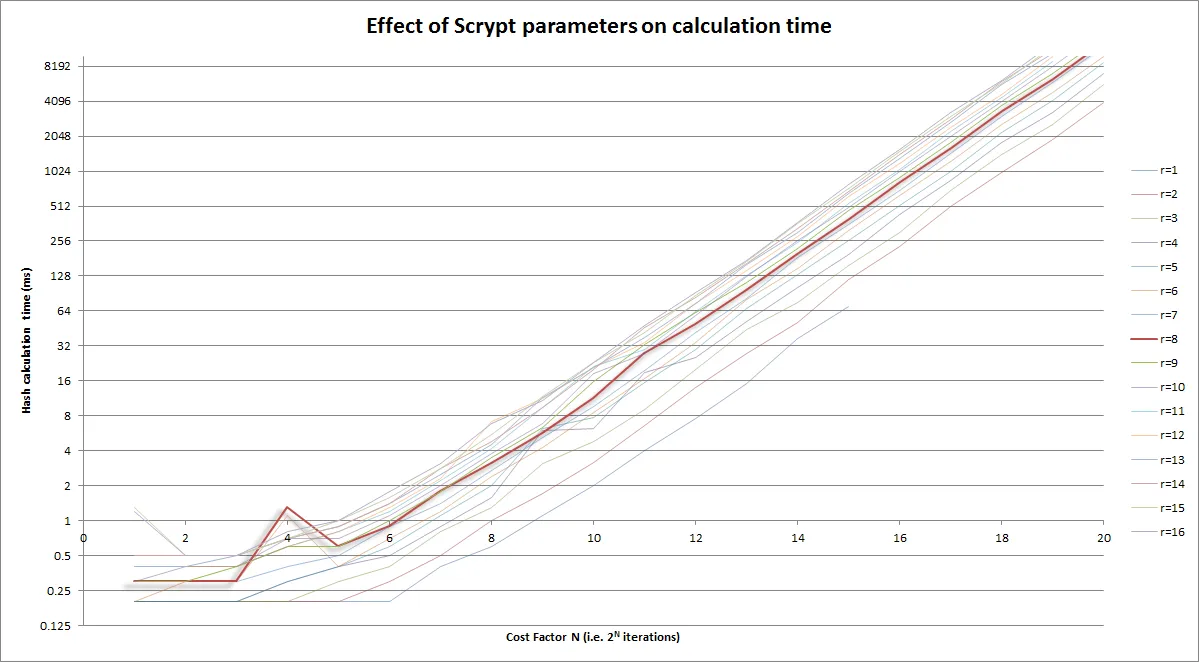
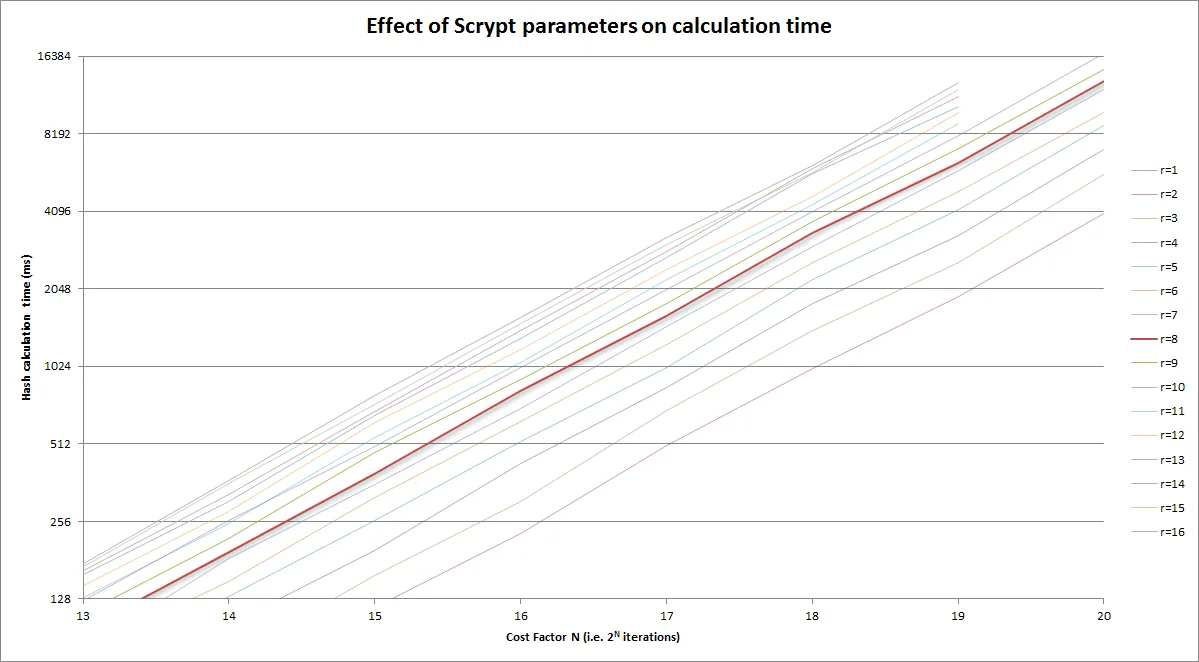
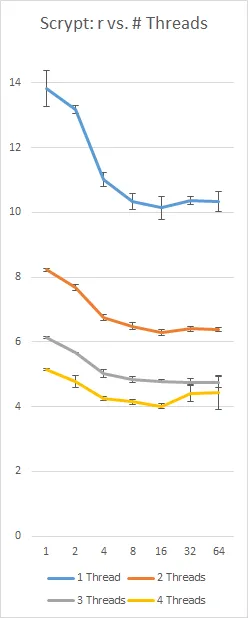
N、r和p值,文档称之为"CPU cost"、"memory cost"和"parallelization cost"参数。问题是,我不知道它们具体意味着什么,或者它们的好值是多少;也许它们与Colin Percival's original app上的-t、-m和-M开关有某种对应关系吗?请问有人对此有什么建议吗?该库本身列出了N = 16384、r = 8和p = 1,但我不知道这是强还是弱,或者是什么意思。